Visit Demo Site
Introduction
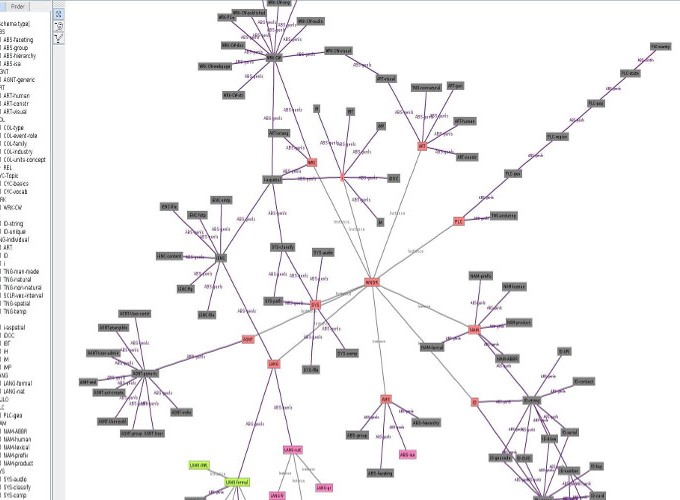
Neurorganon Upper Level Ontology (NULON) is a top-level ontology also known as a foundation ontology. It includes a list of very general terms grouped in ontological distinct categories , such as address , agent, artifact, device, document, space, time and many others. These categories determine the most fundamental and the broadest classes of information resources. In NULON members of each class, i.e. vocabulary terms, preserve the same meaning across more specific knowledge domains and other reference work. In that aspect it is similar to a thesaurus because it groups together terms in disjoint collections of mostly similar concepts and it is like a dictionary because it can also include multiple, multi-lingual definitions. It is also an ontology because it defines relations and properties that describe how the terms can be linked together or bind them to web, computerized information resources. NULON recent version, numbers more than 500 core vocabulary terms grouped in 47 maximally disjoint categories. All these terms have been consistently mapped to standard definitions from at least two major reference works in the realm of semantically linked data; OpenCyc and Wikipedia. Respectively their information resources are used as identifiers and references for NULON terms. Most important, at this stage of architectural design what makes NULON really different from other Upper-Level Ontologies is the kind of grouping of the terms and the categories included and described in the οntology. This is the result of a big effort, the whole year, from a single person, to discover and organize efficiently most terms related to information technology, including abstraction, management, computer programming, data storage, metadata, data modeling, identity, reference, design patterns, web use, digital resources and devices to name a few of them.
From NEURON to NULON
A computer is a general purpose, programmable electronic device, for storing and processing data. From the era of personal computers to the age of mobile devices, we are storing data into files and web pages. We are processing electronic documents with myriads of formats. We organize our file collections into hierarchies with folders. We use them to share information. So far the digital document is the main vehicle of information exchange and at the same time the obstacle for effective management of information and interconnection of information systems. Information technology industry is still waiting for the promised revolution in terms of web software and services.
This partly happened with Web 2.0, the social collaborative user environment that made the need to escape from the document centric computing more urgent. The published content has to be independent of the container so that it can be viewed in many alternative ways and combined easily in many forms. In all these years of computing evolution, there is very little that has been achieved to bridge the gap that exists between the presentation of information to the user and the storage of information on the computer.
But what if we could unify and standardize the processing of information from the lowest level of storing data up to the highest level of consuming the data as interconnected pipeline services. Then the flow of information, the interoperability of services and the communication among users can be achieved by defining a new kind of data abstraction that will enhance and gradually replace the electronic document. This is the information resource/reference (IR) a term that is so confused and obscure in Semantic Web technologies.
You can now start drawing the analogy from computer networks to neural networks. IR is the fundamental unit of processing similar to “neuron”, and the Neurorganon project has already implemented IR in NULON (Neurorganon Upper Level Ontology), a solid theoretical framework that is the foundation for linking concepts together and attaching binary information resources (BIRs). With NULON we can model any kind of data as a graph with nodes (IRs) and edges (associations) and store permanently the network of information in state of the art database management systems that are also based in graphs, the perfect marriage for data modeling.
Most important, with NULON it is now possible to reuse, redesign, repurpose, recombine and interconnect existing software tools for extraction, integration, transformation and visualization of information. Tools will be commercialized, or offered for free, as services and will be used to connect NULON to Web Browser Applications and Graph databases. Eventually we foresee the empowerment of a user with a decentralized network of services that will place him or his community group in charge of a personalized, specialized knowledge graph that will be tailored to his needs.
Finally, with respect to organized information, new browsing methods will appear on the web. These will be present in the form of linked autonomous networks of concepts that will be either automatically created or semi-automatically designed by the expert user again with the help of software as a service. There has to be control for the level of detail and the depth of information, as well as a highly interactive environment to experiment with the visualization of data and the various templates that will assist in the dissemination of information from and to the user.
Arguably the most challenging aspect on this kind of megaproject is to make the user to feel in a natural and comfortable way as it is most often the case when he is browsing the internet or when he sends an email to a friend. One has to experience the new environment and the services in relation to other internet users and tasks that he/she is already accustomed to accomplishing.
The team behind the Neurorganon/NULO project will be aligned with that scope in mind, and the experience and skills of the members involved will eventually guarantee a mature and viable technology and methodology that will lead the development of new generation products and services in the information technology industry.