
TRIADB associative, semiotic, hypergraph technology is an emerging unique and valuable technology in NoSQL database modelling and BI analytics. TRIADB prototype is founded on R3DM/S3DM conceptual model and it was implemented on top of Intersystems Cache database with a command line interface (CLI) in Python (Jupyter - Pandas).
The following video is from a presentation and demonstration of TRIADB at Connected Data London conference on the 16th of November 2017. The event brings together top class innovators, thought leaders and practitioners in the field of Artificial Intelligence and Semantic Technology.
Unfortunately the light conditions were not ideal for the demonstration of our system. We recommend you visit the links at the right side of the following table to view Pandas notebooks in addition to the video above. You may also start the video at the corresponding time.
| Time | Pandas Notebook |
|---|---|
| 05:00 | Traversal and Hypergraph |
| 09:00 | Hypernodes, Hyperedges and Tuples |
| 11:45 | Hypercollections |
| 13:00 | Data Model |
| 15:30 | Mapping |
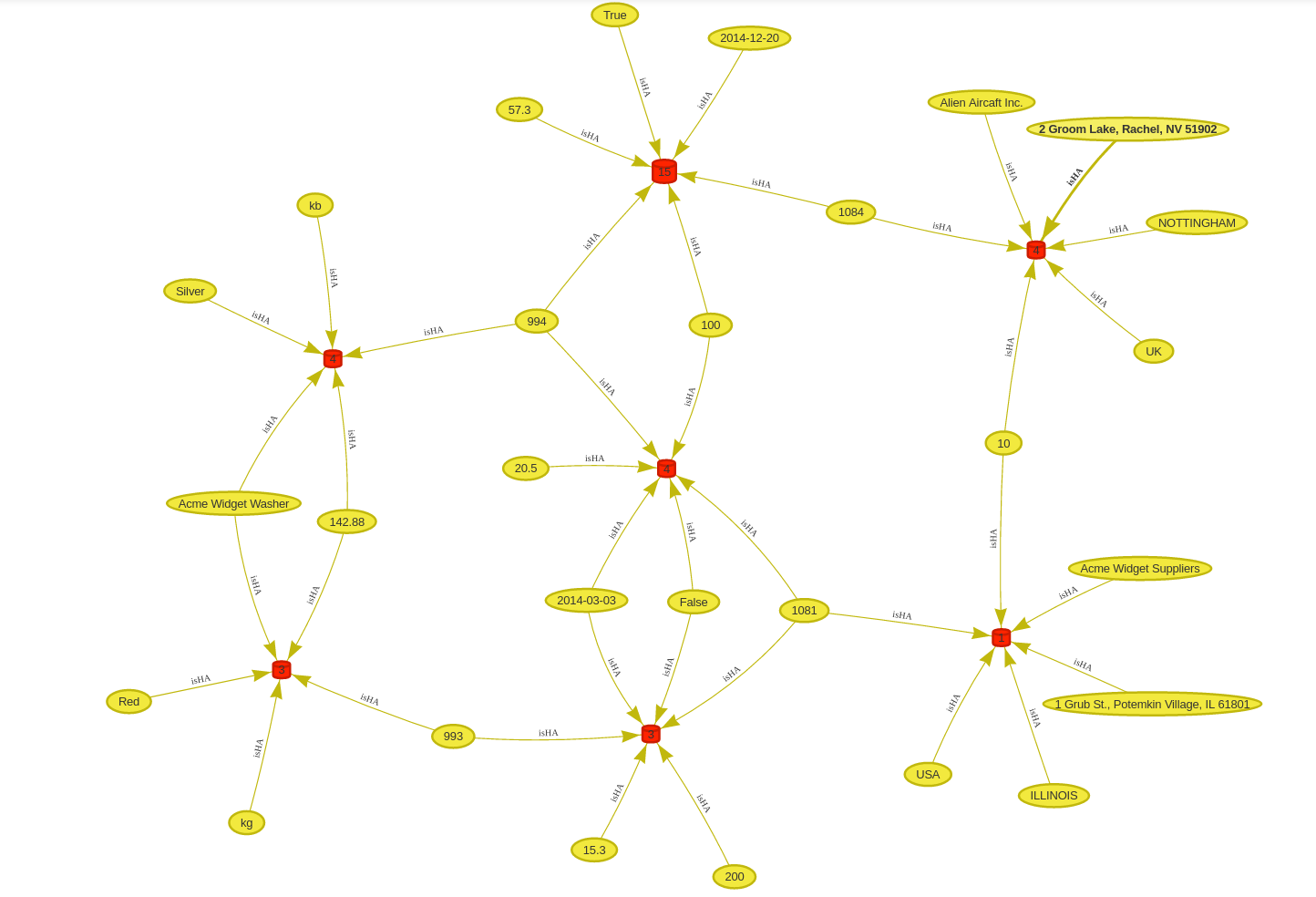


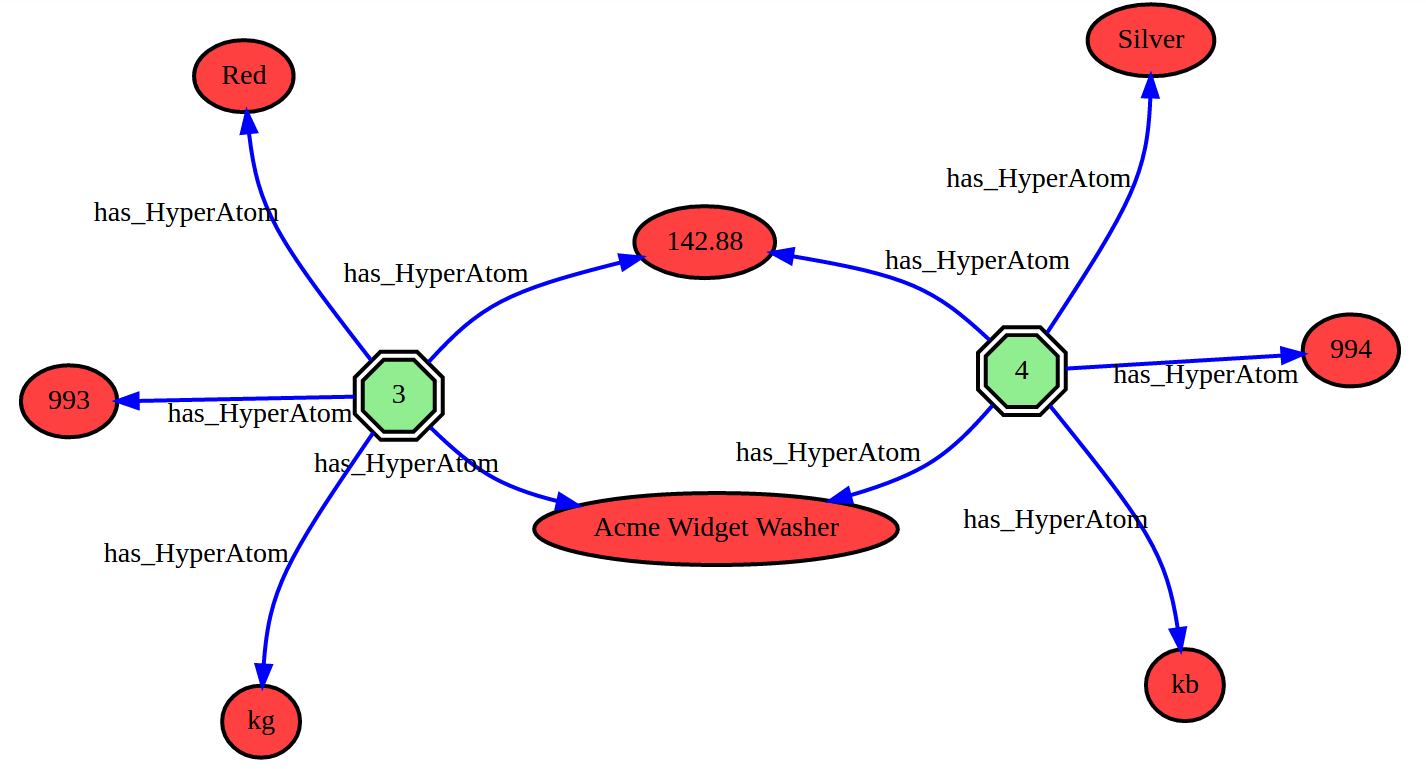


The first two images of our collection portray a hypegraph of seven records, two on the left (Parts), three in the center (Catalog Entries) and another two on the right (Suppliers). The main difference is that in the first one nodes are shown with values and in the second one with 2D numerical references. Images are aligned so you can switch back and forth with the left and right arrow keys.
The third image shows execution of TRIADB Python commands on a Jupyter notebook. This is a traversal query that fetches the tuples that make the neighbourhood of the two parts that we saw in the first two images.
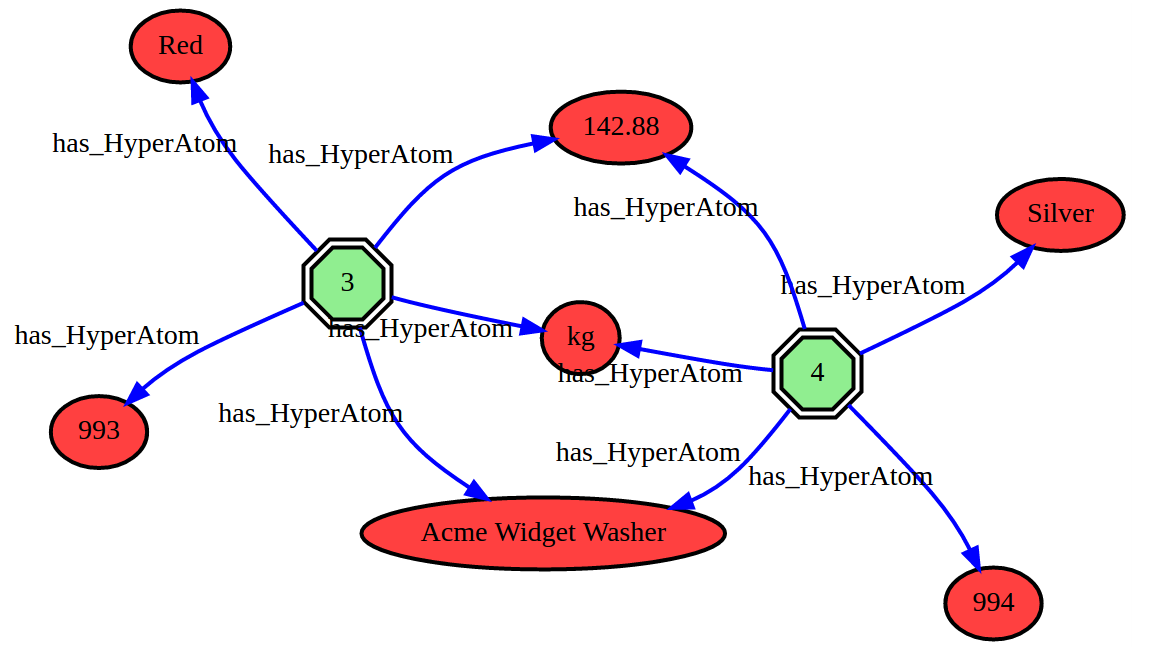
In the fourth image two records are drawn, they have common values for the weight and the name of the part. There is a red (partID=993) and a silver (partID=994) Acme Widget Washer but they do not share a common unit for the weight. This cleansing problem is solved in the fifth image where the two parts share three common values.
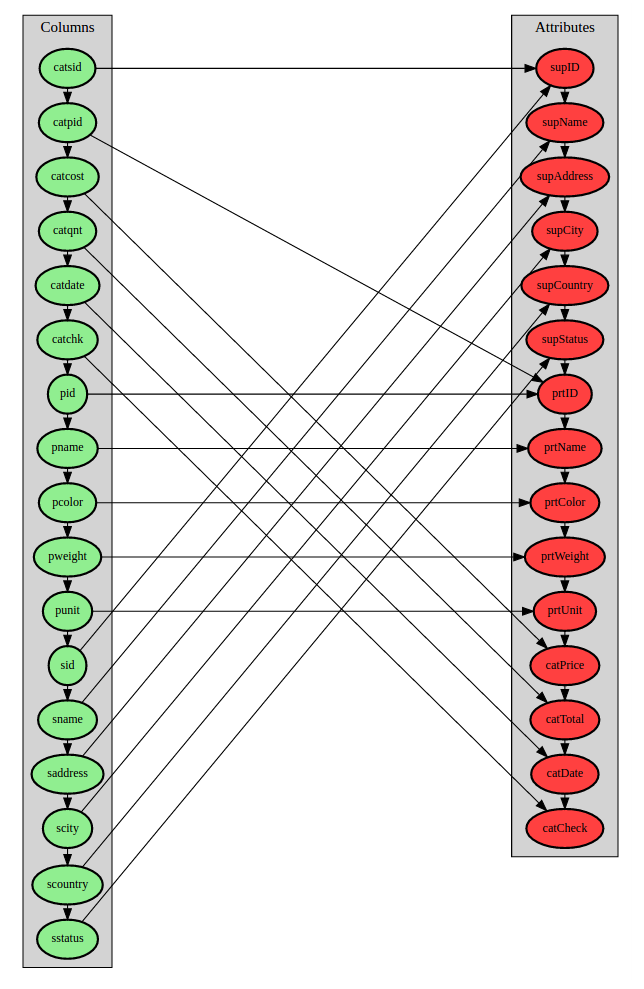
The sixth image visualizes the bipartite mapping solution. The fields on the left are mapped onto attributes on the right and the pandas 2D frame in the seventh image presents their names and key references.
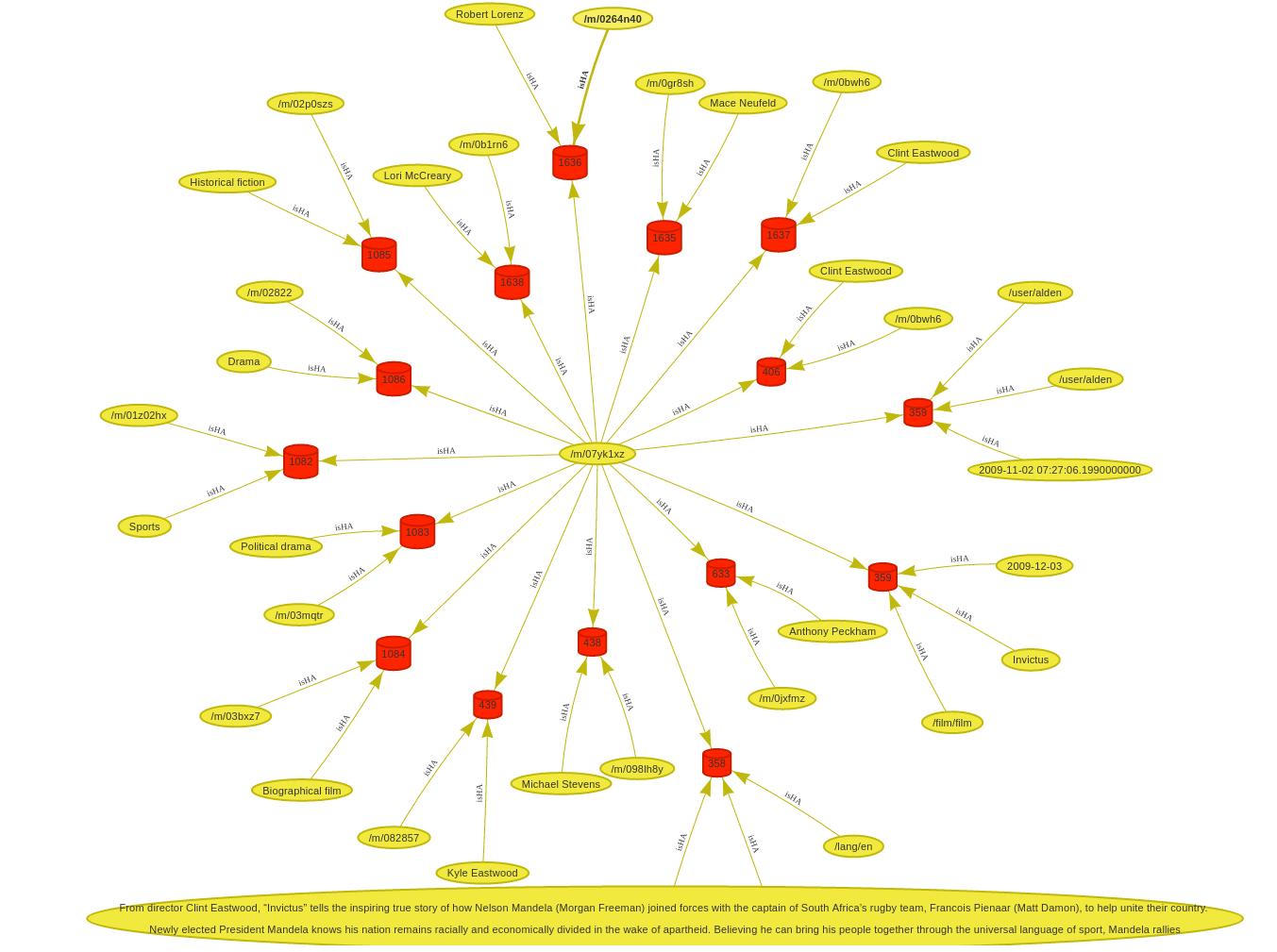
Finally the last two images display a hypergraph data model for movies and a movie instance with many participants. Again you can switch back and forth with the left and right arrow keys.
Screencast of TRIADB on a toy problem dataset with a junction table (Catalog) that bridges the other two tables (Supplier and Part). Videos demonstrate in detail the python client API functional operations of TRIADB system such as add models, add resources and records, get operations to retrieve data and hypergraph traversal operations.
There are five videos in this playlist of HEALIS youtube channel. You may start watching the last video of this series to get an overall impression of TRIADB
In this recording session we demonstrate the first Jupyter Notebook. We show how to use TRIADB functional commands to reset and rebuild the framework. And we explain a bit the associatve and semiotic architectural design of our framework.
In this video you will learn how to add a data model, how to search and retrieve information from the data model environment of TRIADB framework and how to visualize your data model.
In this video we continue with adding resources, mapping these resources to the data model and finally adding records into TRIADB.
In this video we continue with GET operations on Supplier-Part-Catalog data set and we describe various environments according to S3DM/R3DM data model. These include the Data Types Environment (DTE), Data Values Environment (DVE), Data Resources Environment (DRE), Data Models Environment (DME) and Data Sets Environment (DSE).
In this video, first we explain the hypergraph visual representation of our data model, then we compare it with relational data model and finally we traverse the hypergraph.
We would like to thank Intersystems Cache for providing us with a license of Caché DBMS to test TRIADB.