Table of Contents
TRIADB is discontinued, page is maintained here for the history.
At A Glance
TRIADB is an innovative, multi-perspective database framework. It is a Python library that sits on top of suitable NoSQL/SQL data store engines and enables the users to perform easily integration, correlation, aggregation and hypergraph exploration of multiple data resources. TRIADB is founded on the principles of R3DM/S3DM.
Architectural Design
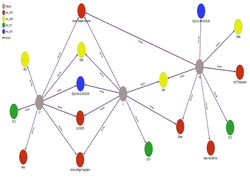
In terms of the architectural design TRIADB is based on associative, semiotic, hypergraph technology pioneered by Dr. Athanassios I. Hatzis. Foundational principles, theoretical formalization and ontological dimensions of the framework and the data model are dating back to the year 2012. Our technology shares certain similarities with Qlik associative technology, AtomicDB and X10SYS associative technology, Sentences associative data model, Topic Maps data model and correlation database model. The main difference of our technology from other similar associative technologies is that it has a solid theoretical background, a unified data modeling architecture and at the same time it is distinct in its design and implementation.
Architectural Overview (White Paper)
Implementations
There are four TRIADB prototypes implemented:
- TRIADB on OrientDB with Mathematica - 2016
- TRIADB on Intersystems Cache with Python - 2017
- TRIADB on Redis with Python - 2018
- TRIADB on MariaDB and ClickHouse with Python - 2019
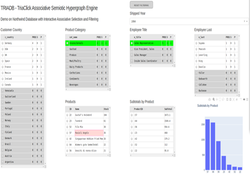
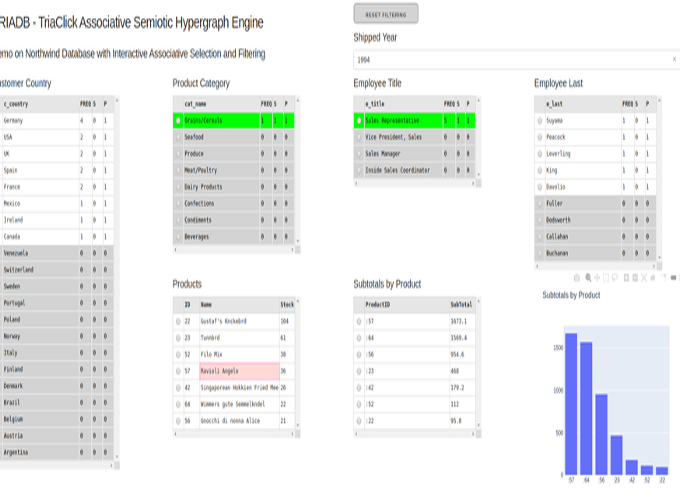
In the last open-source release of TRIADB, MariaDB stores data dictionary information and ClickHouse data storage engines are used for processing and querying data. The associative, semiotic, hypergraph engine has a proprietary licence, although the sources are included in the release, and it is given the codename TriaClick.
Conference Presentations
- 16/11/2017 - Connected Data London Conference
- 19/06/2017 - European Wolfram Technology Conference in Amsterdam
Key Differentiating Factors
The following is a list of technical specifications and features in the design and implementation of TRIADB. This same list is what makes TRIADB a unique and valuable product:
- Multi-Perspective Database Framework: tuples, domain sets, objects, hypergraph, hierarchical
- Act both as an operational and data warehouse database with a 360 degree view
- Automatic fixed, primary indexing schema instead of user-defined secondary indexing
- Manage the references instead of data: relying on reference-based associations and logical identifiers
- No duplicates: single value instance based on system defined primitive data types
- Consolidation of multiple data resources and mapping on user-defined data models
- Management of data resources, data models and metadata
- Python Chain Query Language (CQL) that avoids namespace and impedance mismatch problem
- Interactive, free-form, contextual queries
Business Strategy
We create strong partnerships with database vendors to implement and fine-tune TRIADB on top of their technology stack and we offer consulting services on how to apply Associative, Semiotic, Hypergraph technology. We are not selling licenses or software, we provide full stack solutions and add-on value for our own clients, or for the clients of the vendor, thus the system we build inherits the scaling, performance, availability and TCO of the vendor.
Our associative, semiotic, hypergraph technology is open-source. We are seeking for developer’s community consensus on the use of it and we strongly believe that our technology will be eventually adapted by major semantic and database technology players in the IT industry.