Table of Contents
Introduction to RDF
In the previous post, Part-3, of this series we explored the Property Graph data model. It is now time to write about another Graph data model with a long history behind it, the Resource-Description-Framework (RDF). We will see how we can define an association in RDF and what are the differences with other data models that we analyzed in previous posts of our series.
RDF is a graph-based data model that has been designed to represent information as a labeled directed graph. In RDF, a description of a resource, i.e. any type of thing, is represented as a number of triples. Each triple has a subject, predicate, and object. Alternatively if you want to think in terms of Entity-Relationship model, these three parts of the triple become the Entity-Attribute-Value. This is also known as the EAV model. For instance the Entity subject Part:998 of our Parts table in the example data set of our series can be serialized in Turtle syntax as :
Part:998 rdf:label "Fire Hydrant Cap"@en ;
schema:color "Red"@en ;
schema:weight "7.2"^^xsd:double ;
schema:unitText "lb"@en ;
dc:identifier "998"^^xsd:int .
These rdf:label, schema:color, schema:weight, schema:unitText, dc:identifier are attributes of this Entity instance and “Fire Hydrant Cap”, “Red”, “7.2”, “lb” and “998” are atomic values with an accompanied data type, see also Fig. 7.
RDF and Linked Data
But RDF is not like any other data model, it has been selected from W3C as one of the Web technologies, together with HTTP and URIs, to extend the hyperlinking of documents to a set of best practices for publishing and interlinking structured data on global scale. Today the term Linked Data refers to these standards, and the extension of the Web is also known as the Semantic Web. The predecessor of RDF, the Semantic Network Model, was formed in the early 1960s. The main difference is that arcs and nodes in RDF are identified using HTTP URIs and dereferenced (i.e., looked up) over the HTTP protocol. If we use N-Triples syntax to serialize the same resource Part:998 we take:
<http://example.org/spc/Part/998> <http://www.w3.org/1999/02/22-rdf-syntax-ns#label> "Fire Hydrant Cap"@en .
<http://example.org/spc/Part/998> <http://schema.org/color> "Red"@en .
<http://example.org/spc/Part/998> <http://schema.org/weight> "7.2"^^<http://www.w3.org/2001/XMLSchema#double> .
<http://example.org/spc/Part/998> <http://schema.org/unitText> "lb"@en .
<http://example.org/spc/Part/998> <http://purl.org/dc/elements/1.1/identifier> "998"^^<http://www.w3.org/2001/XMLSchema#int> .
Notice that the object part of the triple is an RDF literal and datatypes are used to represent values such as strings, numbers and dates. These triples are called Literal triples and describe the properties of resources. In our example these literal triples describe five properties of the Part:998 resource. This type of RDF triples is distinguished from the other type which is RDF Links and describe the relationship between two resources. For example if we want to express with the same syntax all the vendors of Part:998 we will form these triples:
<http://example.org/spc/Part/998> <http://www.wikidata.org/property/hasVendor> <http://example.org/spc/Supplier/1081> .
<http://example.org/spc/Part/998> <http://www.wikidata.org/property/hasVendor> <http://example.org/spc/Supplier/1082> .
<http://example.org/spc/Part/998> <http://www.wikidata.org/property/hasVendor> <http://example.org/spc/Supplier/1083> .
<http://example.org/spc/Part/998> <http://www.wikidata.org/property/hasVendor> <http://example.org/spc/Supplier/1084> .
This is also the equivalent result set at Fig. 1 presented in a compact form from the following SPARQL query:
#Suppliers of Part 998
PREFIX Supplier: <http://example.org/spc/Supplier/>
PREFIX Part: <http://example.org/spc/Part/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX wd: <http://www.wikidata.org/property/>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
select ?prt ?p ?sup where
{
BIND(wd:hasVendor AS ?p)
# Start with a ?prt that has id=998
?prt dc:identifier "998"^^xsd:int .
# Find all catalog items (?cat) with a reference to ?prt
?cat wd:hasPart ?prt .
# For any catalog item (?cat) find the vendor that supplies ?prt
?cat ?p ?sup .
}
Result set from SPARQL query to find the suppliers of Part:98

In Fig. 1 The URI with QName wd:hasVendor, in the predicate position defines the type of relationship between a subject with QName Part:998 and an object with any of these QNames (Supplier:1081, Supplier:1082, Supplier:1083, Supplier:1084). Both subject and object URIs are in the same namespace (http://example.org/spc/), these are called Internal RDF links.
One way to think these RDF links is as a labeled directed graph. Each triple is a directed arc that connects a subject, e.g. Part:998, with an object, e.g. Supplier:1084, and the predicate is the label of the arc, wd:hasVendor. For example the previous result set can be represented with the following graph in Fig. 2:
Suppliers of Part:998

But the graph for the data model of our example is slightly more complicated because there are intermediate nodes, i.e. inventory items that represent records from the Catalog table, that associate, bridge Suppliers with Parts Fig. 3.
Suppliers of Part:998 with intermediate Inventory Items nodes

Another distinction of RDF links to Outgoing and Incoming can be seen in Fig. 3. For example Part:998 has four incoming RDF links of type wd:hasPart and Item:7 has two outgoing RDF links of type wd:hasPart and wd:hasVendor respectively.
In fact the SPARQL query above has been written taking in consideration this graph. In order to traverse the nodes you must know both the type of RDF link and its direction. In RDF graph data model edges are unidirectional. In order to define bidirectional edges we have to define both outgoing and incoming RDF links for each node, i.e. two predicates Fig. 4.
RDF bidirectional

Association in RDF
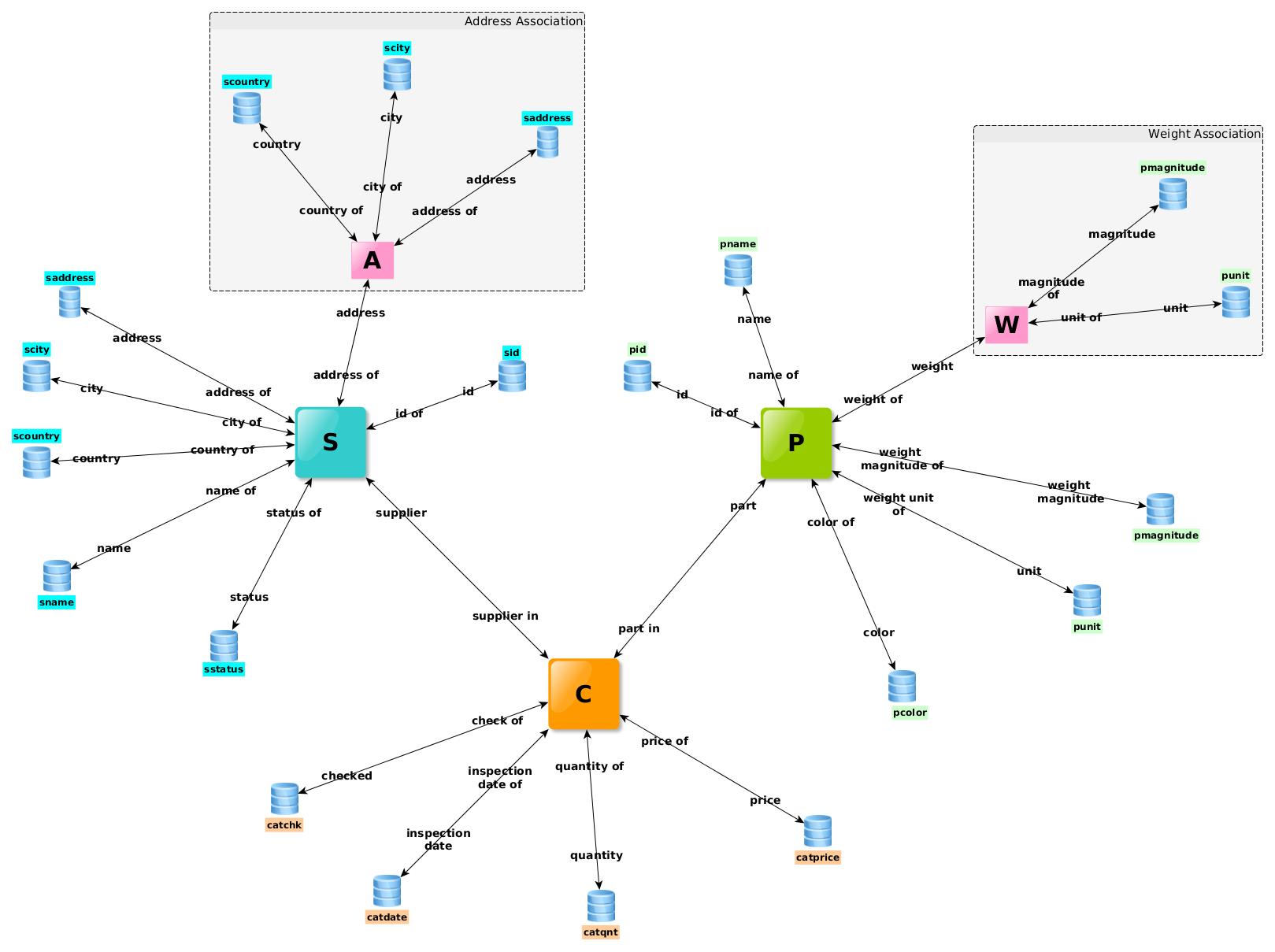
We can now compare these five associations of Part:998 with RDF links of the graph in Fig. 6. One of them is composed with all outgoing triples of Part:998, i.e. Part:998 is the subject of the triple Fig. 5. These literal triples describe five properties of Part:998 resource, yellow boxes of Fig. 6, and another RDF link is for the type of resource, i.e. Item (grey box).
# Get all outgoing triples for a specific part
PREFIX Part: <http://example.org/spc/Part/>
select ?prt ?p ?o where
{
BIND(Part:998 AS ?prt)
?prt ?p ?o .
}
Result set of all outgoing triples for 
Part:998
The resource Part:998 participates in four associations with Inventory resources, as the object of a triple. These are the four incoming RDF links of Part:998 in Fig. 3, Fig. 6 and Fig. 8.
Five associations of 
Part:998, four with the green boxes and one with the yellow boxes
We can write the following SPARQL query to ask for all the suppliers of Part:998 sorted by their catalog price.
#Suppliers of Part 998 (Red Fire Hydrant Cap) sorted by their catalog price
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX wd: <http://www.wikidata.org/property/>
PREFIX schema: <http://schema.org/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
select ?sup ?supName ?supCountry ?catPrice ?catQuantity ?prt ?prtName ?prtColor ?cat where
{
# Start with a ?prt that has id=998 get its name and color values
?prt dc:identifier "998"^^xsd:int .
?prt rdf:label ?prtName .
?prt schema:color ?prtColor .
# Find all catalog items (?cat) with a reference to ?prt get their price and quantity values
?cat wd:hasPart ?prt .
?cat schema:cost ?catPrice
OPTIONAL {?cat schema:quantity ?catQuantity .}
# For any catalog item (?cat) find the vendor that supplies ?prt get their name and the country of origin
?cat wd:hasVendor ?sup .
?sup rdf:label ?supName .
?sup schema:country ?supCountry
}
ORDER BY ASC(?catPrice)
You may consider the analogy between this query and the result set at Fig. 7 and the equivalent OrientDB SQL query and the result set from a Property Graph data model. The main differences are that in Property Graph data model you can traverse edges in both directions, (incoming, outcoming), the filtering part (where) in SPARQL is significantly longer, and the starting point is represented in a different manner (edge vs link).
Suppliers of Part 998 (Red Fire Hydrant Cap) sorted by their catalog price

fig7
Associations of 
Part:998 with Suppliers and their Catalog prices
We can view a graph representation, Fig. 8, of this SPARQL query and its result data set Fig. 7. In the same screen capture, Fig. 8, a many-to-many relationship is modeled with RDF triples. Supplier:1082 is associated with three parts (Part:991, Part:997 and Part:998) and Part998 is associated with four suppliers (Supplier:1081, Supplier:1082, Supplier:1083, Supplier:1084), see also Fig. 9. From a semantic point of view, Parts and Suppliers participate in associations with Inventory items (green boxes - Catalog:7, Catalog:9, Catalog:10, Catalog:11, Catalog:12 and Catalog:16). In contrast with the binary relations between Suppliers and Parts represented with directed edges in a Property Graph, see here, instead of an edge type we have explicit intermediate (bridge) nodes and instead of outgoing head (out) and incoming tail (in) we have two outgoing directional links (wd:hasPart and wd:hasVendor) from this intermediate node, e.g. Catalog/Inventory item to Supplier and Part. In such as case these outgoing directional links (wd:hasPart and wd:hasVendor) look like roles in a Topic Map binary association.
/* 4 Associations of catalog part no 998 with supplier Ids and catalog prices */
Catalog07( Part998:HasPart, Supplier1081:HasVendor, 11.7:Cost )
Catalog11( Part998:HasPart, Supplier1082:HasVendor, 7.95:Cost )
Catalog12( Part998:HasPart, Supplier1083:HasVendor, 12.5:Cost )
Catalog16( Part998:HasPart, Supplier1084:HasVendor, 48.6:Cost )
A Many-to-Many Relationship between Suppliers and Parts modeled with RDF triples

Associative Model
Although it has not become mainstream, we see associative model of data as an effort to enhance RDF data model in a new kind of DBMS. The logical layer of Sentences associative database management system may be regarded as comprising of only two tables: one for Items that represent Entities, Entity Types, Values and Value Types and one for Links that represent among other things Associations and Association Types ([Fig. 15], [Fig. 16]). Both Items and Links also represent meta-types and instances, which perform various functions in the database. Thanks to this simple consistent form of Items and Links, it is easy to write generic code that is capable of working with every type of data. Recording schema changes and transactions, a type system [Fig. 15], associative queries in the form of a request tree, business rules, data provenance, automated default data entry forms [Fig. 16] and many other features of Sentences DBMS were designed and implemented based on this generic metacode programming.
Types, Association Instances and their Properties
Types, Entity Instances and Data Entry Forms


In fact along similar principles Freebase collaborative knowledge base, now known as Google’s Knowledge Graph, was serving its users.
Both Freebase and Sentences added also reverse edges to their model. In Freebase notation, [Fig. 10] we can see that /film/film is /directed_by a /film/director and a /film/director has directed (/film) a /film/film.
Movies Data Model in Freebase

Bidirectional links allow a 360° view of every data item in the database. Directed edges in Property Graph share the same concept, see here. In the following three figures (Fig. 11, Fig. 12, Fig. 13) we present three alternative schema views for our Supplier-Part-Catalog database that we built on Sentences DBMS. Fig. 11 illustrates that it is possible to add attributes on the link. Fig. 12 shows that Supplier, Catalog and Part entities are sharing common attributes while in Fig. 13 they are directly connected with bidirectional links.

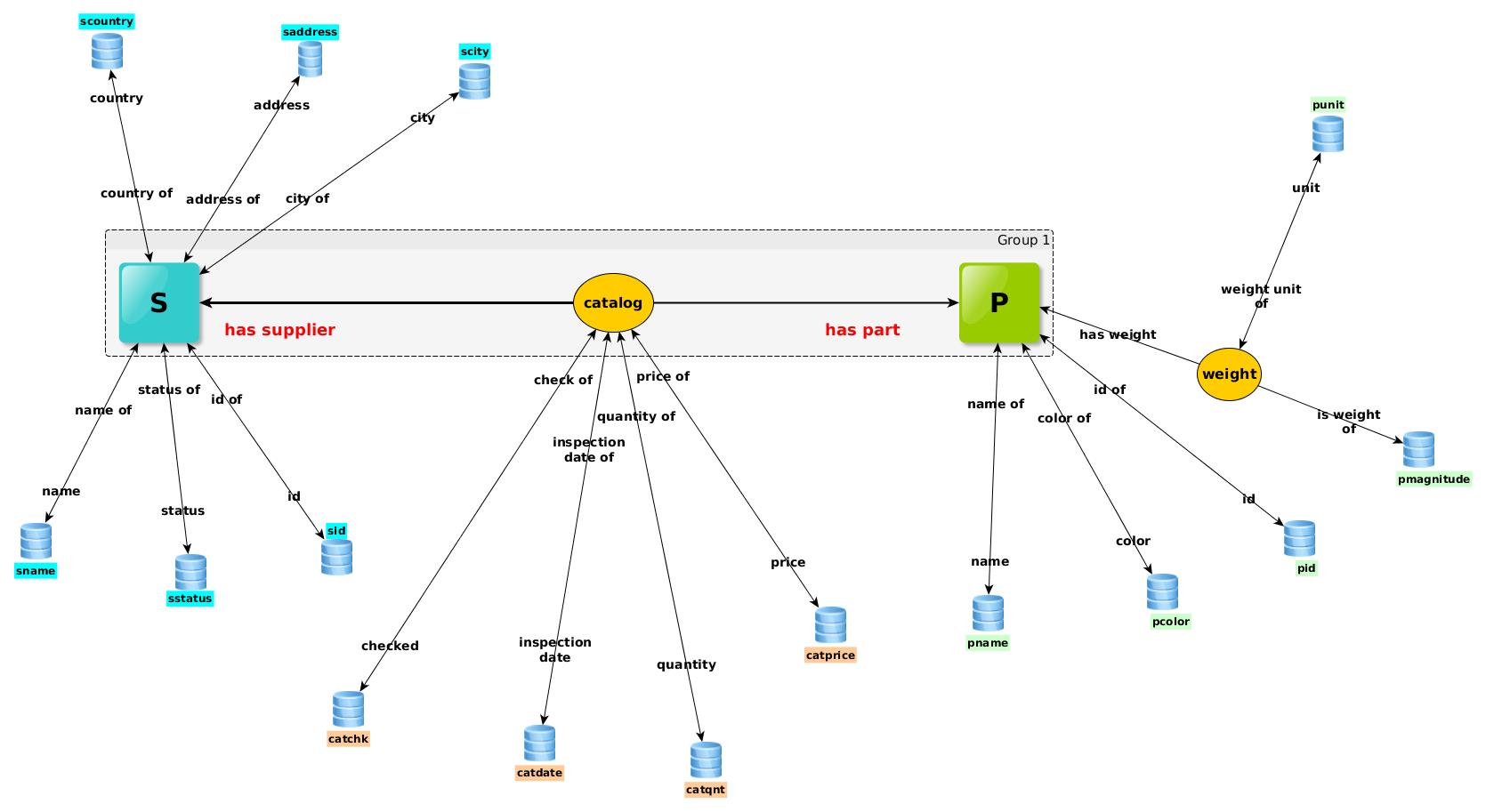
Association in R3DM
According to R3DM Hypergaph Terminology, the objects of RDF literal triples, i.e. values, are HyperAtoms and the resources of RDF links are HyperBonds. Thus the RDF graph of Fig. 8 can be redrawn as a hypergraph with red nodes that play the role of HyperAtoms and green nodes that play the role of HyperBonds, see Fig. 14.
R3DM Hypergraph

This R3DM hypergraph figure above, Fig. 14, has been created from the execution of the following Wolfram Language code. You will notice that HyperAtom sets such as ha2-(catcost) and ha5-(catqnt) are attribute sets with value members that take part in the formation of Catalog records with instances that are drawn from hb2 set. Supplier instances are drawn from the other HyperBond set (hb3) and ha3-(sname), ha4-(scountry) are attribute sets with value members that describe the Suppliers. Instances from these HyperBond sets may share common values or associated with the same HyperBond. For example we have two suppliers, Supplier:1082 and Supplier:1081 that are located in USA or Catalog:11 and Catalog:16 entries that are associated with Part:998 and they both have the same quantity, i.e. 200 pieces of this part.
ha1={998,"Fire Hydrant Cap","Red",7.2`,"lb"};
ha2={11.7,7.95,12.5,48.6};
ha3={"Acme Widget Suppliers","Big Red Tool and Die","Perfunctory Parts","Alien Aircaft Inc."};
ha4={"USA","USA","SPAIN","UK"};
ha5={"400","200","200"};
hb1={"Part:998","schema:item"};
hb2={"Catalog:7","Catalog:11","Catalog:12","Catalog:16"};
hb3={"Supplier:1081","Supplier:1082","Supplier:1083","Supplier:1084"};
vstyle=Join[Thread[Join[ha1,ha2, ha3,ha4,ha5]->Red],Thread[Join[hb1,hb2,hb3]->Green]];
data=Join[
{"Part:998"->"schema:item"},
Thread["Part:998"->ha1],Thread[hb2->ha2],
Thread[hb2->hb3],Thread[hb3->ha3],
Thread[hb3->ha4],Thread[hb2->"Part:998"],
Thread[{"Catalog:7","Catalog:11","Catalog:16"}->ha5]];
Graph[
data,
VertexLabels->"Name",
VertexSize->{{"Nearest",0.15}},
VertexStyle->vstyle,
EdgeShapeFunction->GraphElementData[{"CarvedArrow","ArrowSize"->.02}],
EdgeStyle->Thick,
GraphLayout->"SpringEmbedding",
ImageSize->{400.,Automatic}
]
We can rewrite now the following four associations :
/* 4 Associations of catalog part no 998 with supplier Ids and catalog prices */
CatalogID( catpid, catsid, catqnt, catcost)
Catalog07( Part998, Supplier1081, 400, 11.70 )
Catalog11( Part998, Supplier1082, 200, 7.95 )
Catalog12( Part998, Supplier1083, 12.50 )
Catalog16( Part998, Supplier1084, 200, 48.60 )
Associations in this form greatly resemble tuples of Catalog relation, see TSV format, where the heading of this relation is usually stored in a data dictionary and Null marker indicates that a data value is absent from the tuple. On the contrary in case of RDF literal triples the predicate position signifies the object part of the triple and in RDF links Instances/Type of resources at subject and object positions are also signified by predicates such as (rdf:type). But in R3DM associations there is not any label on the edge that connects HyperAtoms or HyperBonds. Therefore the denotation of resources and literals, i.e. what they stand for, cannot be seen on this graph, Fig. 14. For example in Catalog12 association instance we have to know that the literal meaning of the value 12.5 is the Catalog Cost. Generally speaking, this is the granularity of data problem. How we represent a piece of information at atomic level and how we construct higher structures. R3DM/S3DM unifies three perspectives, semantics at the conceptual layer, representation at the symbol layer and encoding at the physical layer, in such a way that they are separable. R3DM/S3DM conceptual framework is based on the natural process of semiosis where the signified, i.e. concept, entity, attribute and the signifier, i.e. value, are referenced through symbols, i.e. signs, at discrete layers. The main difference with RDF data model is that these references are not in the form of URIs but they resemble IPs. For example the value 12.50 can be referenced by a 4D vector of the form {2, 8, 262, 1} where the first dimension is the database, the second dimension is the table (Entity), the third dimension is the field (Attribute) and the last dimension is a member of an attribute set.
Discussion
Although this is not the space or the time to elaborate more on R3DM/S3DM associations it is important to mention that it is possible to escape from the predicate logic (owl#sameAs) on how to identify that two URI aliases refer to the same entity. Moreover the alternative paradigm of R3DM/S3DM offers a more attractive and efficient approach on data integration and heterogeneous data representation than bridging between RDF vocabularies with mapping predicates such as owl:equivalentClass and owl:equivalentProperty.
We foresee that the Internet of things will use a protocol with numerical reference vectors for data communication in a similar fashion to IP addresses that are used for connecting devices in a computer network. Hopefully one day it will become clear that the predicate part of RDF data model is causing more harm than good in the semantic interpretation and information representation.
Last but not least, SPARQL query mechanism is heavily dependent on namespace vocabulary terms, especially predicate terms that connect resources and literals. To answer such queries, care must be taken to devise a suitable mechanism of indexes (e.g. spo, sop, pso, pos, osp, ops) to support RDF triple structure. Besides indexing, RDF edges by default are not bidirectional, therefore 360 degrees view and nodes navigation is problematic. In contrast with RDF, in R3DM/S3DM everything is bidirectionally linked and referenced with 4D numerical vectors and these are naturally used for indexing purposes. Instead of writing queries there is a functional way, i.e. you learn a single command with a standard number of optional or mandatory parameters, to filter the data space and retrieve any piece of information.
Interactive and associative data exploration is the key, unique feature of Qlikview/Qliksense, one of the best data visualization and business intelligence software in the market today. Behind the scenes, columnar, binary indexing capability is the foundation for QIX Associative Data Indexing Engine. In the next part of our series we will apply Qlik associative technology on our toy dataset and we will demonstrate how we build the domain model and how we filter our data.
Acknowledgements
We have serialized our Supplier-Part-Catalogue example in Turtle and N-Triples syntax. Then we used AllegroGraph and GraphDB triple-store to create a repository and run queries on their SPARQL interfaces. All graph-based images of this article were displayed and captured on Gruff, an RDF visual browser that displays a variety of the relationships in AllegroGraph.
Cross-References
- LinkedIn Published Posts
- LinkedIn Semantic Web Group
- LinkedIn Graph Databases Group
- LinkedIn Data Warehouse & Business Intelligence Architects
- LinkedIn Computational Semiotics
- LinkedIn Semantic Technologies
- LinkedIn Data Visualization
- LinkedIn Database & Data Store Professionals ★ NoSQL ★ NewSQL ★ Relational
- LinkedIn Database Developers and Architects Group
- LinkedIn Linked Data Web
- LinkedIn Mathematica Users
- LinkedIn Database Experts
- DZone Article