Table of Contents
Introduction to Qlik’s Associative Model
In the discussion session of the previous post of our series we mentioned two basic reasons that make RDF data modeling and consequently SPARQL query mechanism disadvantageous with an interactive and associative data exploration and data integration as that of QlikView/Qliksense. These are the naming of predicate terms that connect resources and literals and the unidirectional architectural design of the edges. We have already demonstrated this issue with the associative model schema design of a Movies domain in Freebase, Fig.12, and the modeling of our Supplier-Parts-Catalogue toy example in Sentences, Fig.15, Fig.16 and OrientDB Property Graph, Fig.4. In this post we continue our journey with Qlik’s associative data model.
Qlik’s In-Memory Associative Architecture
Qlik’s competitive advantage over other BI tools is that it manages associations in memory at the engine level and not at the application level [(English,2010)]1. This management of data, is deep down to an atomic level of data (Granularity), i.e. every data point in every field of a table is associated with every other data point anywhere in the entire schema [(English,2010)]1. We will follow Qlik’x QIX engine stepwise approach with the goal of performing an interactive data exploration [(Ferguson,2015,p.10)]2 of our Suppliers-Parts-Catalogue data set.
Loading the data
The first step is to bring data into memory. A multi-table read-only, in-memory, compressed, binary, columnar data model is created. Data from each source data table is converted into two types of in memory data structure : [(Ferguson,2015,p.12)]2.
- A set of columns that contain binary values, i.e. references, for each distinct original value.
- A compressed binary data table by replacing each row/column cell value with a binary reference.
For example, the following statements, [QlikView script syntax, p.242]3, load data from the Parts and Suppliers tables that are stored in Excel files and reconstruct eleven unique columns and two read-only binary representation of these tables in memory.
LOAD prtID, prtName, prtColor, prtWeight, prtUnit
FROM [F:\tmp\SupplierPartCatalogue\SuppliersPartsCatalogue.xlsx]
(ooxml, embedded labels, table is Part);
LOAD supID, supName, supAddress, supCity, supCountry, supStatus
FROM [F:\tmp\SupplierPartCatalogue\SuppliersPartsCatalogue.xlsx]
(ooxml, embedded labels, table is Supplier);
If two fields have the same name in two different tables (i.e. a relationship) then they have the same columnar binary representation. In order to resolve ambiguities and to associate over fields that have the same name, unique column naming is required. This is the case for our third associative, i.e. bridge, junction table. Field names catSID and catPID have already been loaded and represented with the columns supID and prtID. The next LOAD statement is using the alias operator (as) to handle unique column naming.
LOAD catSID as supID, catPID as prtID, catPrice, catTotal, catDate, catChk
FROM [F:\tmp\SupplierPartCatalogue\SuppliersPartsCatalogue.xlsx]
(ooxml, embedded labels, table is Catalogue);
QlikView Internal/Source Table View
Once the script is executed we can review the data table structure, Fig. 1, with the Table Viewer. The three tables are associated with two connectors that bidirectionally link them through their common fields. This layout is quite similar with the Entity-Relationship diagram of Microsoft Access database schema, Fig.5. A QlikView association resembles a SQL natural outer join. However, an outer join in SQL is unidirectional. An association always results in a full (bidirectional) linkage. In practice we have two completely different approaches. In a typical SQL join query we repeatedly search the index because of the join condition.
QlikView associative engine (QIX) knows how every data point is associated, therefore it can effectively determine (infers) and flag all distinct column values and all rows in each data table upon user’s selection 2
The Blind Spot
Depending only on memory, QlikView can load many whole tables without joins, instead of a limited view from the main dataset. Other query-based BI tools usually aggregate an extracted subset of data and return it in the form of a result set. This result set is completely divorced from the original data set and this very act of extraction breaks associations. For example, find out how a piece of data contained in a query relates to another piece of data outside the query [(QlikView Whitepaper, October 2010, p.3)]4. You may think also of an internal combustion engine analogy . With the query-based paradigm, we would look at individual parts of the engine in isolation, (see the header image of our post). Using QlikView associative technology, we have access to a digital model of a complete working engine and we can tweak any part to see how that affects other parts and the engine on the whole.
Explore/Filter Data via Selections
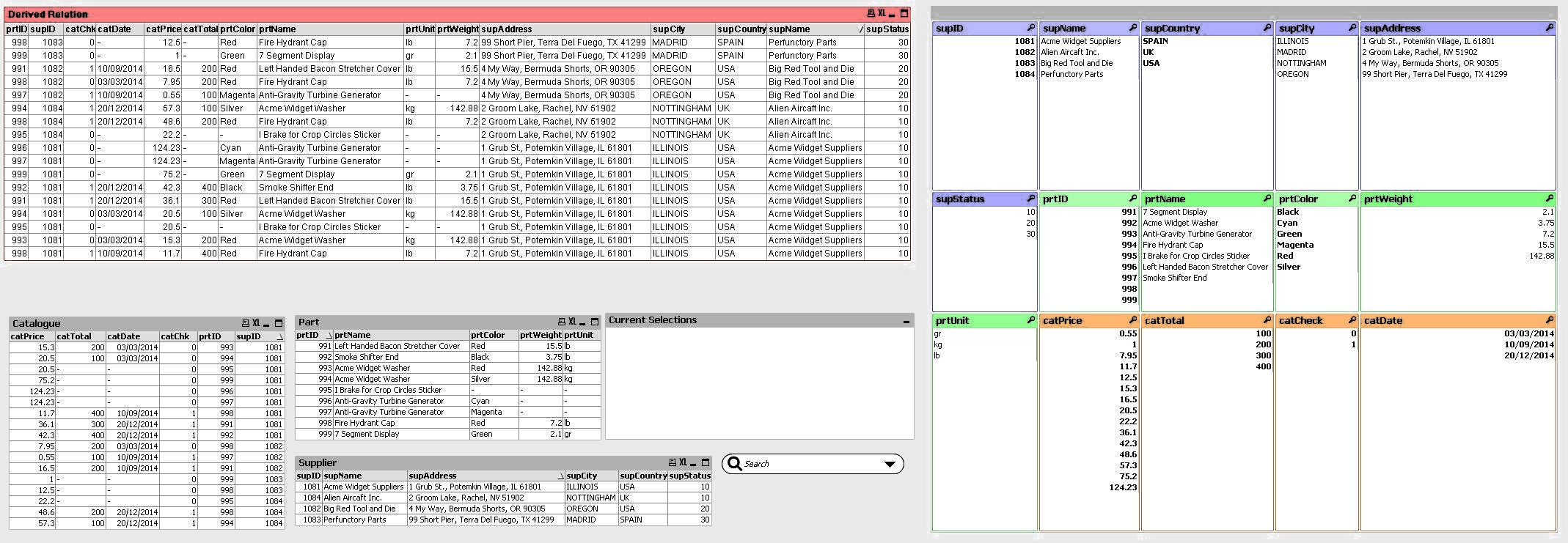
In this section we will examine QlikView associative aspect from the user’s experience point of view. “Central to QlikView is the concept of a user-defined selection state. As users click around in a QlikView document, they indicate which subsets of data they are interested in analyzing and which subsets should be ignored, [(QlikView Whitepaper, September 2011, p.10)]5. To demonstrate the visual effect of associations, i.e. the relationship between a value in one field and a value in another, we arranged a number of [Sheet Objects, p.457]3 in our Main worksheet. We chose [Table Boxes, p.507]3 to present rows of data from our Tables and [List Boxes, p.459]3 to display a list of all possible values of a specific field. We have also added a [Current Selections Box, p.519]3 to list user’s selected field values and a [Search Object, p.569]3 for searching for information anywhere in the document, Fig.2.
QlikView Sheet Object in an unselected state with Table Boxes, Current Selections, and a Search Box on the left side and a Container with List Boxes for Fields representation on the right side
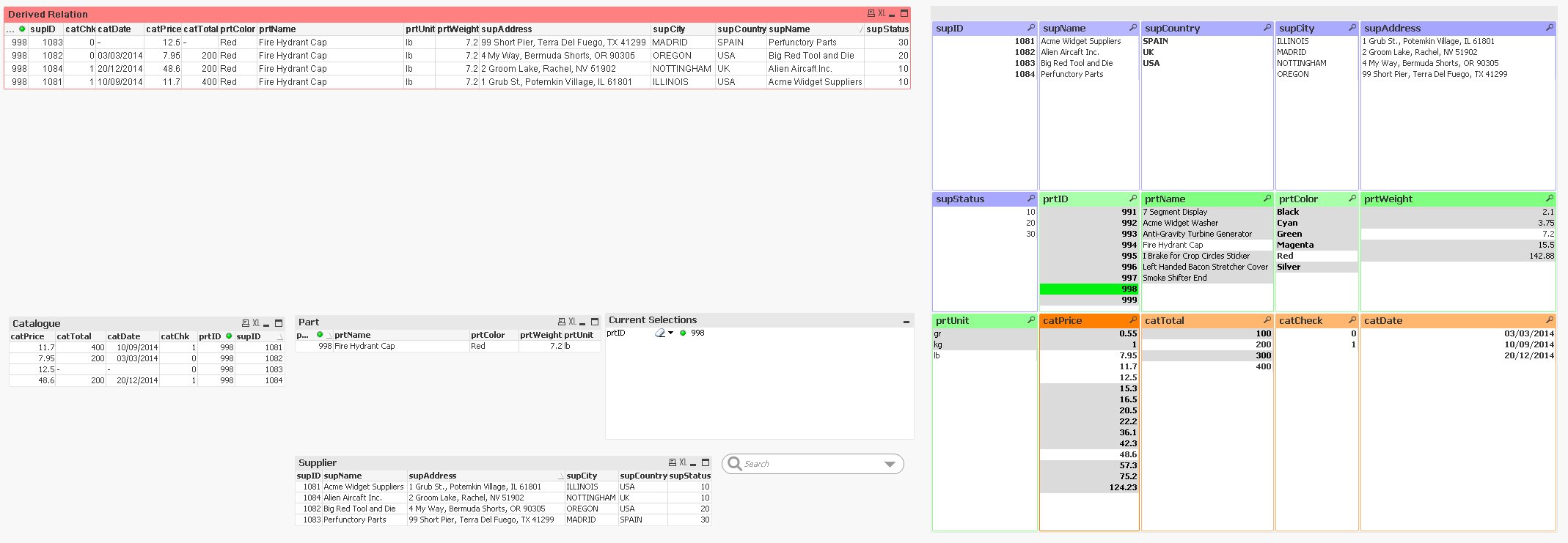
Now you can see visually what is associated and is not associated with any particular selection. For instance, [Fig.3]3 displays the state of our Worksheet when the user selected the Part item with ID value equal to 998. The List Box of the field (prtID) with the value 998 appears in green and it has also been added to the Current Selections list. In other List Boxes, unrelated values in all other fields appear in gray and those that are related appear in white. At the same time, when the user interacts with this particular List Box all the rows of Table Boxes are instantly filtered to reflect this new context.
Table Boxes on the left side are filtered and values of the List Boxes on the right appear in white or gray according to the current selection (green)
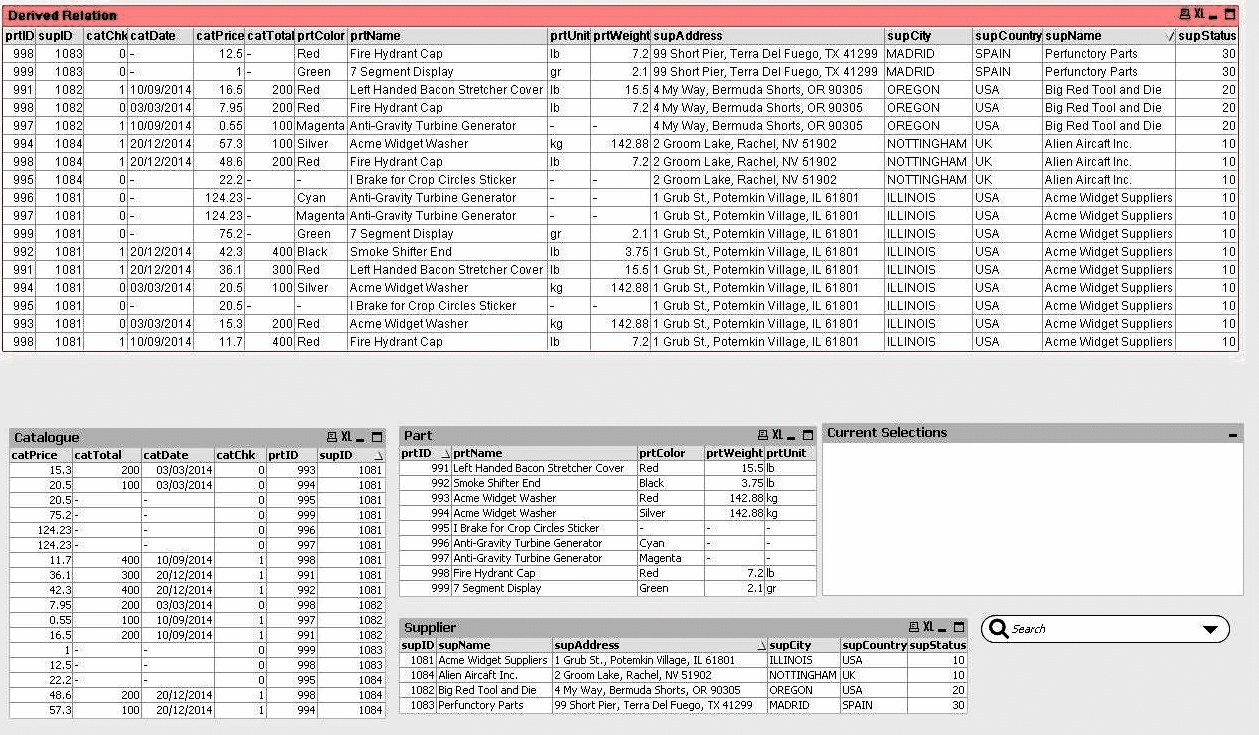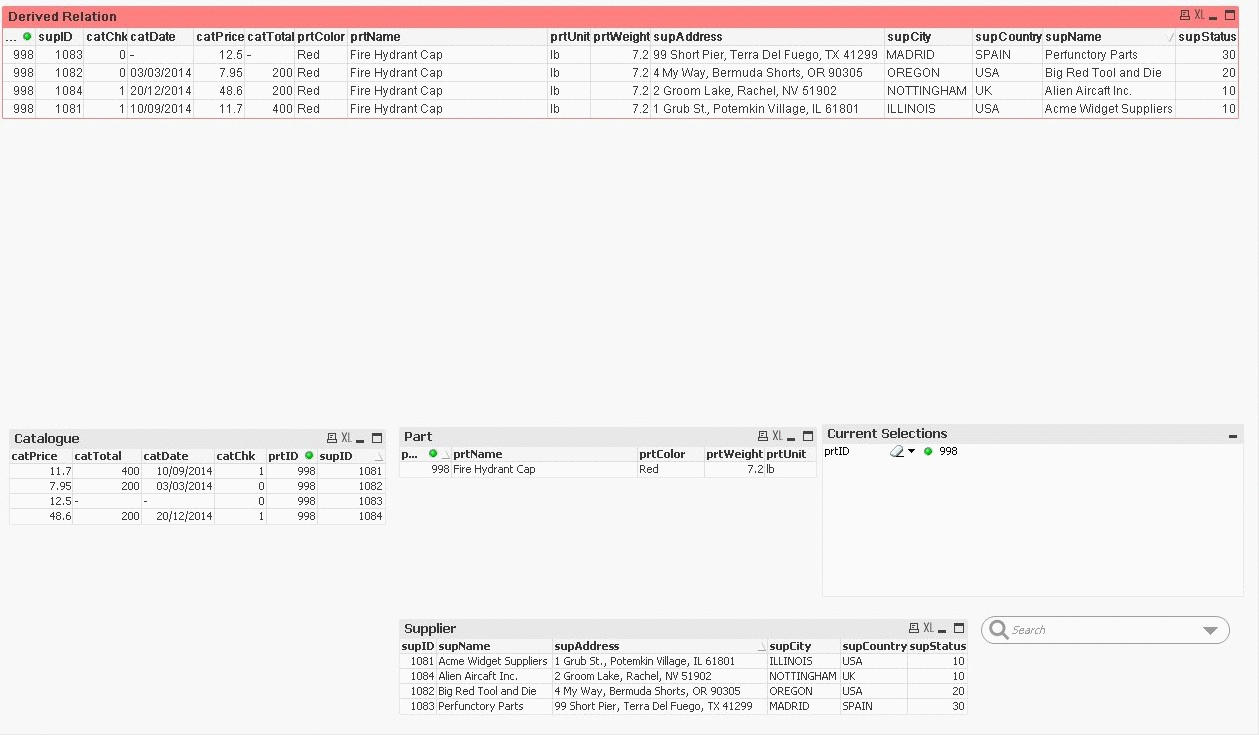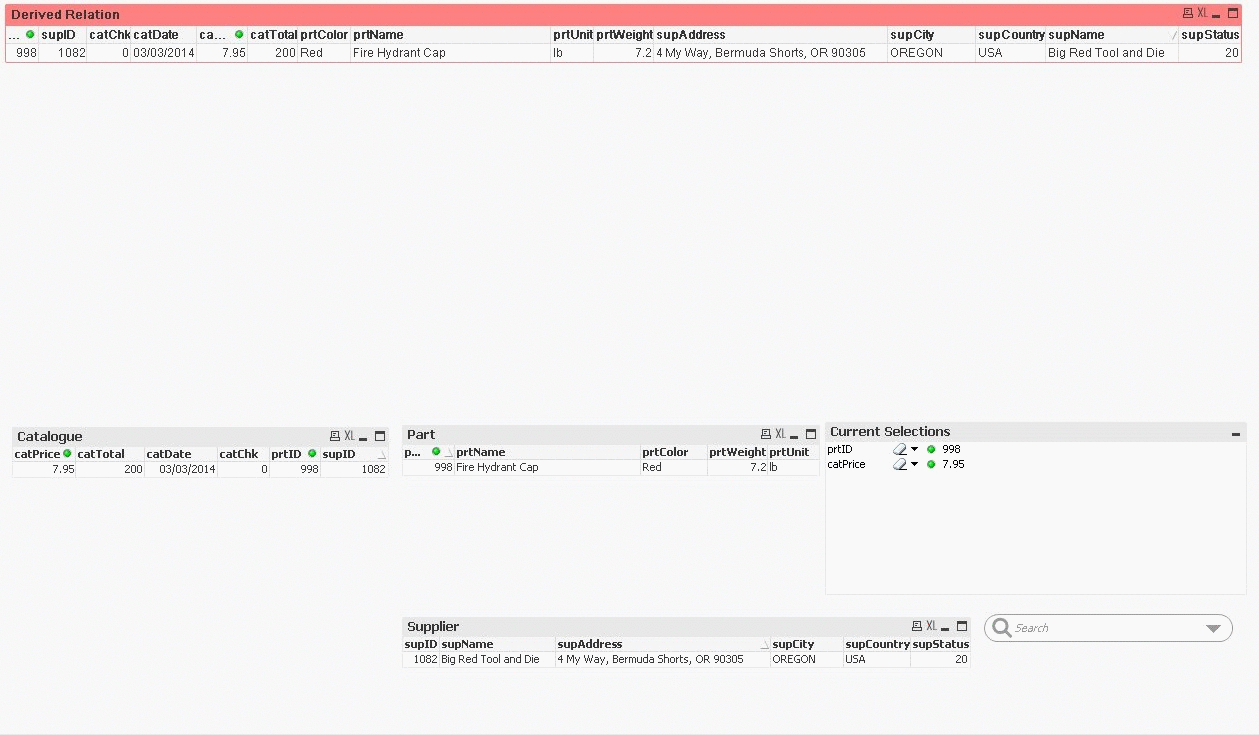
So far we have seen how we can get the resulting data after user’s selection in two possible formats, a list of values (List Box) for each field of the data Table, Fig.5, and a grid (Table Box) with tuples (records), Fig.4. You may also notice in our visual setup that we have a Derived Relation red grid with selected fields from all three Tables of our data set. This grid is automatically constructed with those tuples that appear in the other three grids (Catalogue Table Box, Part Table Box and Supplier Table Box). We should make it clear that the update of this Derived Relation under the hood is not performing any kind of Join (SQL) operation. The effect of tuples filtering and shading of list values is demonstrated with animated gif images in three states. There is the Unselected State, then there is the Part with ID value 998 selected state, and from those Catalog entries for this specific Part, (4 entries, one for each Supplier), we select the Supplier with the minimum Catalog price and that is our third state.
Animated Grids of Tuples
Animated Lists of Values from Table Fields
R3DM Hypergraph Representation
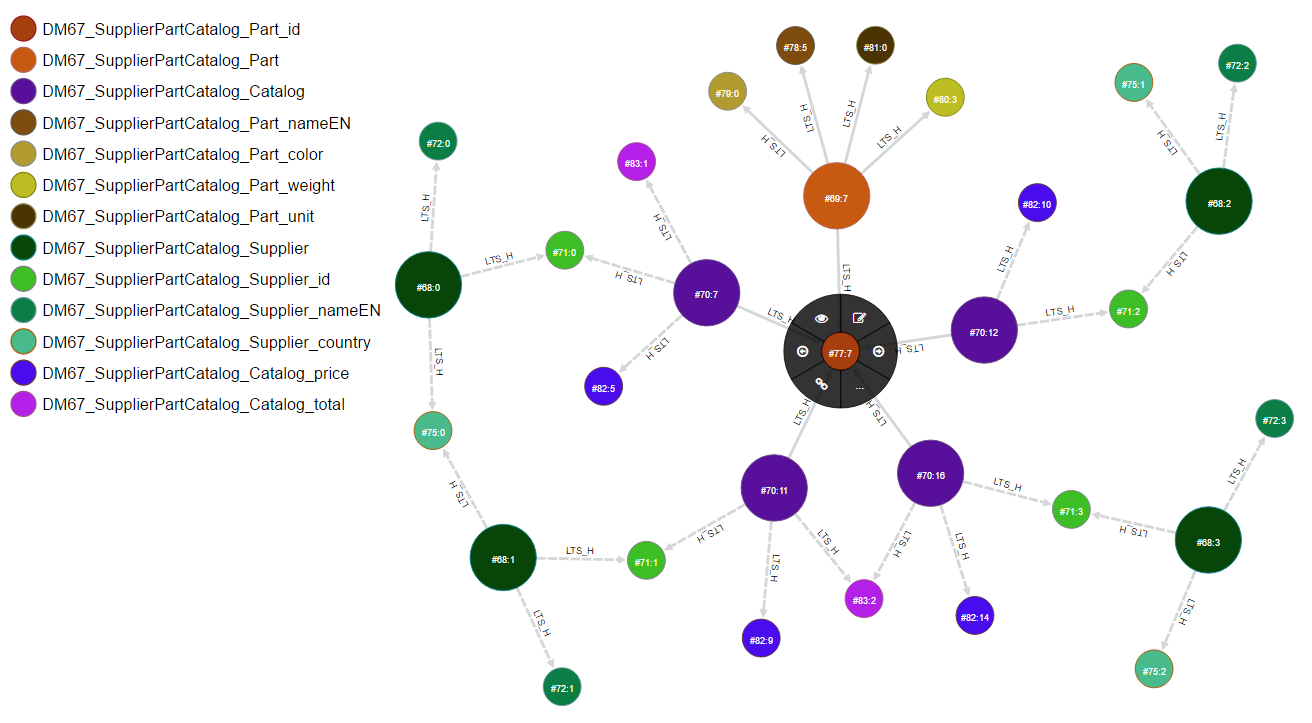
With the Associative Data Modeling there can be a third way to present data. This is the one that engages the user with the visualization of network graphs. In the previous post of our series, we have drawn an R3DM Hypergraph, Fig. 14, and we described associations according to R3DM terminology. We have used exactly the same data of this case study example, i.e. find the Supplier with the minimum Catalog price for Part with prtID value 998, to draw Fig.2 , Fig.3 , Fig.4 and Fig.5 . This time we have redrawn hypergraph of Fig. 14 with the help of OrientDB Graph Editor, Fig.6. Every string label and numerical value of Fig. 14 has been replaced with a unique OrientDB record identifier, (RID - clusterID : clusterPosition). In effect, this is how we implemented R3DM/S3DM Sign layer. Each data item becomes an Atomic Information Resource (AIR) unit with a symbolic representation of a 2D vector (Entity/Attribute Type : Instance).
AIR Units
From Data Items in any structure (Table/Entity/Triple/JSON/XML) to data model reconstruction with Information Atoms
AIR units can represent in a uniform way anything, i.e. Entities, Attributes, Values, Types, Databases, etc. Their vector form can be indexed, linked, retrieved, stored efficiently, and we can use AIR units to build associations and assimilate composite information structures such as records (tuples).
To visualize R3DM associations using AIR units we have color coded the graph and we added a legend at the left side, Fig.6. Entities are distinguished from attributes by the size of the disk and grouping of entities and attributes is depicted with different shades of a color (green for Suppliers, brown for Parts, purple for Catalog items). We can easily see four Catalog items (#70:7, #70:11, #70:12, #70:16) associations with the four Suppliers (#68:0, #68:1, #68:2, #68:3) and the Part (#69:7) with ID value 998 (#77:7) that is drawn in the center of the graph with the black disk around it. USA suppliers (#68:0, #68:1) share the value of their common supCountry attribute (#75:0). One of them (#68:1) has a Catalog entry (#70:11) with the minimum catalog price,catPrice, (#82:9). We can also see the formation of tuples for Supplier (4), Catalog (4) and Part (1).
R3DM Color Coded Associations with AIR units
Regarding to the immense advantage of using AIR units to reconstruct hierarchical, table, or graph structures, we can also refer to the following QlikTech patent. In the “Summary of the Invention” section we read:
each different data element value of each data element type is assigned a binary code and the data records are stored in binary-coded form. On account of the binary coding, very rapid searches can be conducted in the tables. - Qliktech International AB Patent, May 20016
Future Plans
It is rather unfortunate that the basis of QlikView’s evolutionary associative technology has been confined to the market of proprietary software products. In HEALIS we have made the difference by opening up these database design key principles for discussion with experts of the field and we have made them part of our R3DM/S3DM conceptual framework.
We have gone a step further to implement our framework on top of OrientDB and Intersystems Cache DBMS and instead of writing SQL queries, we have abstracted the programming of a set of functional operations that match the selection and filtering of data. We plan to continue with the last part of this post series in order to fully demonstrate how we build our system and how we test it with the Suppliers-Parts-Catalogue data set.
Cross-References
- LinkedIn - Published Posts
- LinkedIn - Semantic Web Research Group
- LinkedIn - Graph Databases Group
- LinkedIn - Data Warehouse & Business Intelligence Architects
- LinkedIn - Computational Semiotics
- LinkedIn - Semantic Technologies
- LinkedIn - Data Visualization
- LinkedIn - Database & Data Store Professionals ★ NoSQL ★ NewSQL ★ Relational
- LinkedIn - Database Developers and Architects Group
- LinkedIn - Linked Data Web
- LinkedIn - Update
- LinkedIn - Database Experts
- LinkedIn - QlikView
- Qlik Community - German User Group - Post
- Qlik Community - Discussion
-
D. English, “White Paper: Understanding QlikView’s Associative Architecture”, QlikTech International AB, May 2010 ↩︎ ↩︎
-
M. Ferguson, “White Paper: Interactive Data Exploration With An In-Memory Analytics Engine”, QlikTech International AB, May 2015 (pdf) ↩︎ ↩︎ ↩︎
-
“QlikView Reference Manual v11.20 SR2”, QlikTech International AB, Lund, Sweden, 2013 (pdf) ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
“The Associative Experience QlikView’s Overwhelming Advantage”, QlikTech International AB, October 2010 (pdf) ↩︎
-
“QlikView Architectural Overview”, QlikTech International AB, September 2011 (pdf) ↩︎
-
“Method and Device for Extracting Information from a Database”, QlikTech International AB, May 2001 ↩︎