TRIADB is discontinued, page is maintained here for the history.
Self-Service Data Management & Visual Interactive Analytics Framework
This is a public announcement of the second open-source release of TRIADB, codename TRIACLICK. Repository of the project can be found at GitHub.
You can use TRIACLICK to manage your disparate data sources, create custom data models with an integrated, whole view of your business and get a business insight by building easily dashboard web applications that work with the associative selection/filtering of Triaclick engine.
Tutorial and Installation Guides
Analytic instructions on how to install TRIADB are written on the installation guide. If you decide to go deeper, read the tutorial guide to get into the basics of programming with TRIADB.
Screen Capture Demo
Watch a screencast demonstration of the main features of TRIADB in the current release with a focus on the key aspects highlighted and illustrated in the following section.
At A Glance
TRIADB is an innovative, multi-perspective development framework written in Python with the scope to assist power BI users and developers to build easily web applications and/or Jupyter notebooks, i.e. reports, that are based on interactive computing and exploratory, visual analysis. It’s main unique and valuable characteristics are:
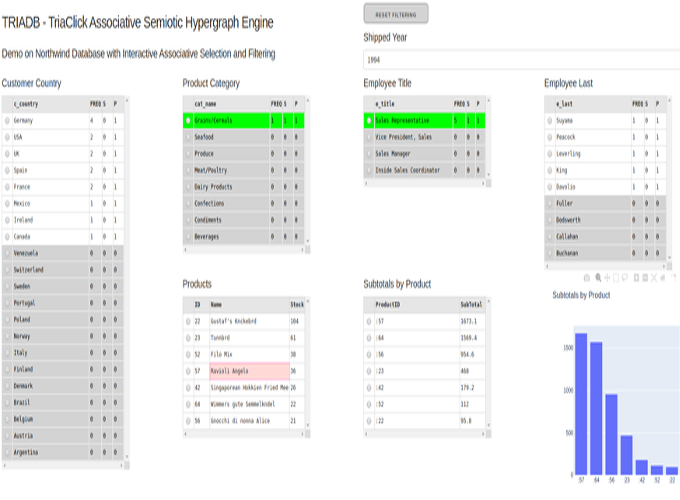
- Interactive visual exploratory analytics powered by TriaClick associative semiotic hypergraph engine. The technology is based on ClickHouse columnar DBMS and its output can be easily transformed to enable hypergraph traversal, associative selection and cross-filtering with states on coordinated visualizations.

TRIACLICK Animated Chart
Coordinated update of GUI components based on associative selection and filtering

TRIACLICK Hypergraph
Visualization of hypergraph paths based on TRIACLICK associations
- User defined business models in the form of a hypergraph. Data modeling plays a central role in TRIADB. Management of meta-data, loading and filtering processes are innately related, associated, with the business model you define.

Business Model Graph
Business model based on Northwind database with Associative Entities in yellow
- Interactive programming with high-level OOP components and methods tailored to fit database management and analytics. TRIADB powerful transformations, including list items, tuples and associations enable the user to analyze data quickly and intuitively.

Associative Filtering
Examine visually how the domain set values of attributes are related

Transformation of aggregation
Aggregation in a filtered state and transformation to tuples and bar chart
What problem TRIADB solves and how
The project started long time ago from a personal need to integrate an electronic medical record database used in a neurosurgery clinic with several other specialized databases for neurosurgical disorders. Integration, correlation, aggregation and visual exploration will always be the holy grail of business analytics. Associative technology in general is a specific solution that has not been opened to the public until now although it is applied by one of the most successful BI companies for two decades. The implementation of associative semiotic hypergraph engine (TRIACLICK) in TRIADB project opens a path for other competitive, cost effective (not only RAM based), efficient solutions sharing the same principles in data modeling and database management.
Future Plans
TRIADB is a middleware, one part is closely coupled with the physical layer of the data store engine and the other part is closer to the application layer. Therefore the project can be expanded in two directions, optimization and improvement of associative semiotic hypergraph engine on one hand, efficient and effective transformations and visual exploration on the other hand.
In spite of the growing development of TRIADB which requires urgently funding for resources, the critical factor for the success of this project is how exactly it is going to be applied to solve particular users’ problems. This step requires that users become aware of what are the advantages in using TRIADB and what they can achieve.