Table of Contents
Q&A session on R3DM/S3DM
What is information
In Greek we call it, (plērophoria) from πλήρης (plērēs) “fully” and φέρω (phorein) frequentative of (pherein) to carry through. It means to carry, to convey a message thoroughly, exhaustivelly, in a complete way. It is strongly related to the formation of the message, it depends on the sign vehicle we use to transmit the message.
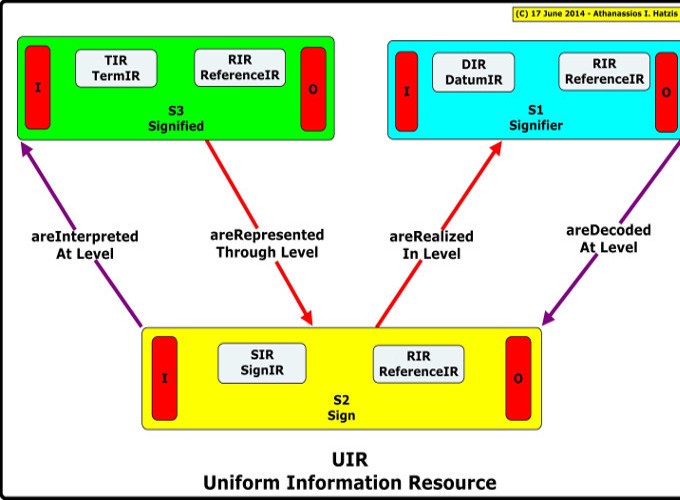
What is an information resource
It is a container of information. In the computer world a data container such as a blog, a web address, physical memory, computer hard disk. In the physical world any object can be an information resource.
What kind of information resources we have
A binary information resource (BIR) is a container of information about concepts related to the computer world, such as a web page, a file, an email, a database record, a programming variable. A term information resource (TIR) is a more generalized concept than BIR. TIR is extended to cover any term in general including those we use in our daily human to human communication. Both BIR and TIR represent abstract concepts. These are constructs that we use at the semantic, ontological layer of R3DM.
What is an information reference
An information reference is the source of information resource. It is where it gets its meaning, it is the place it was originally conceived or defined. Any BIR or TIR is conceived in the human mind in the process of thinking. Therefore it follows naturally that they are referenced accordingly. Human concepts are presented from the sender in a verbal, oral, visual, or written way and are perceived from the receiver. Regarding to the meaning, the semantics of the transmitted information, there is strong connection between the interpretant and the sign vehicle used to carry information. The sign vehicle is strongly dependent on the information reference, i.e. the interpretant. We can have more than one interpretations for the same sign, and likewise any sign is referenced in many ways.
What is information representation
Let us take things from the beginning. We have a concept in a human mind. The concept is presented in some perceivable way with symbols, icons, words, spoken sounds, etc. This represents an object of the real world that we want to talk about. In a computer we use metaphores: for example the desktop environment with files and folders on it. In fact any object of the real world can be represented in many ways on a computer screen: characters, numbers, images, sounds, books.
What is information realization
Everything that is represented in a computer is in fact encoded in a binary format. Any content, such as text for example, can take many forms but at the end it is stored or transmitted in a binary format. In computers, this is the lowest level of information, it is the data level.
Why semantic models like RDF/OWL and TMDM are not sufficient for the semantic web
First let me make something clear. Semantic web is not the web of linked data, it is simply an approximation. In Web 1.0 and 2.0 we were linking documents, e.g. web documents, files. What is different now, is that we also link structured data, from relational databases, from RDF databases. But we are still in the data level. In my opinion Web 3.0 has to be differentiated from the current web, it has to create a distinct layer on top of the existing linked data layer with its own referencing scheme that can be resolved with the current URI scheme. This will have its own way to define and handle terms, concepts, relations, axioms, rules, the structural components of an ontology. The semantic web, is an ontological web. Everything else should revolve around it, data population, ontology enrichment, subject indexing, searching, matching, sharing.
We can not make a significant progress on the “semantic web”, because there is not a model that combines the three main models of information architecture:
- The database model (data level - Information Realization),
- The programming model (symbol level - Information Representation) and
- The semantic model (human level - Information Referencing).
Indeed, there is ongoing research on RDF data model towards a semantic object framework, to bridge the gap between RDF and object-oriented programming and there are also researchers that investigate the mismatch of RDF with graph models and graph databases, especially property graph databases. R3DM is looking into combining those two interpretations of RDF by utilizing a post-relational database and a native object script language.
Is there an analogy of your model with the object-oriented programming paradigm where you have reusable and composable structures
I think the first question that has to be answered, is how we define the fundamental unit of information processing. Remember, in Topic-Maps Data Model everything is a topic. In our writing system, word-lexeme-morpheme, is our fundamental unit. The current progress with graph databases, and the long research with RDF triplets indicate, that indeed, we can define such a unit. Let us call this information node (iNode). The new question you should ask is how exactly these nodes are related. How do we represent relations ? The encoding of information into triplets has started long time ago, both with the Entity-Attribute-Value databases and now with the linked data movement. Although OWL is supposed to bridge the gap between programming and semantic relations, in practise this has never been achieved! A new programming language that will be based on a transparent handling of semantic relations and the corresponding data management is absent. This new programming language must be closely connected to the database layer.
Semantic web or the web of linked data is using URIs to identify and to address information resources, is there a difference in your model
We are trying to develop a new, semantic web, layer on top of the previous one, where the document, i.e. web page, file, etc is the basic unit of information. The two layers can communicate with the current web addressing infrastructure but the new layer MUST have its own referencing scheme. A scheme that will be used both for retrieving and updating purposes. The naming/identification issue is also of critical importance here.
What is the outmost objective with your R3DM data model
The current www is based on content (data) and addressing (hypelinks) and the main founder and visioner of the Web Tim Berner’s Lee cries out “put the data on the web”. But the point is how to represent and link the human knowledge on the web, things like concept maps (Novak), conceptual graphs (Sowa) and these are based on linking concepts, not data. I would like to see the web of linked concepts. I see an obsession in many for machine readable data. The point is how our technology can assist us in making fast and smart decisions, in solving extremely complicate problems of interdisciplinary nature and machine readable data is just part of it.
Domain Independent Abstraction and Kinds of Relations
I think it is fundamental for the improvement of this kind of “Semantic Web”, LinkedData Web, if there is going to be some effort to describe and represent abstraction and relation types. We would not have to deal with such a chaos of alignment and mapping on predicates if there was some generally acceptable template, formula on what kind of Domain Independent Abstractions exist and how we can formulate them.
Part of my R3DM data model and the work in it, is to define such a schema. I will give you a flavour here with an example that is characteristic of the confusion that exists between two specific generic relation types, (1) inheritance-subtyping and (2) hypernymy-hyponymy. Consider the following:
-
(1) Music composition —- isBroaderThan —> Sonata
-
(1) Sonata —- isNarrowerThan —> Music Composition
-
(2) Music Instrument —- isHypernymOf —> Wind Instrument
-
(2) Wind Instrument —- isHyponymOf —> Music Instrument
Notice that both relations are symmetric and we need to define both directions. Each entity plays also a specific role in that relation. Now, if we can find a consistent way to describe relations that will make life much easier for both the developers and the researchers in “Semantic Web” area.
In my opinion, we can define three broad classes of hierarchical relations that create all kinds of taxonomies (read more about them in other recent posts in this group).
-
Generalization-Specialization expressed with the predicates nulon:isBroaderThan and nulon:isNarrowerThan and the roles Superior, Subordinate
-
Hyponymy-Hypernymy expressed with the predicates nulon:isHypernymOf and nulon:isHyponymOf and the roles Hypernym, Hyponym
-
Holonymy-Meronymy expressed with the predicates nulon:isWholeOf and nulon:isPartOf and the roles Whole, Part
Triples can be seen as binary predicates, but n-ary relations is a very natural way of thinking about many things such as events. This is exactly the point of a big divergence among TopicMapDM, RelationalDM, GraphPropertyDM, Freebase DM, Associative DM, RDF/OWL DM and others.
I think modelling n-ary relations is not the root of the problem. The mother of all problems in data modelling is the bootstrap mechanism of creating types and the absence of a single universal Upper Level Ontology as the gold standard to define core basic types. Take Freebase for example, they have defined from scratch their own type system.
This again cannot be seen in isolation of the data structures, a low level issue, that one is using to permanently store or process the data. This is why I insist that software engineers have to think in at least three perspectives of R3DM semiotic data model, i.e. the semantic, the symbolic and the storage.
Cross-References
- LinkedIn - 20130403 Greek IT Network
- LinkedIn - 20130920 Topic Maps Community
- LinkedIn - 20130927 Semantic Web Research
- LinkedIn - 20131129 Computational Semiotics
- LinkedIn - 20131227 Semantic Web Research - Domain Independent Abstraction and Kinds of Relations
- LinkedIn - 20131229 Semantic Web Research - Taxonomy Relations - My perspective
- LinkedIn - 20131129 Computational Semiotics - About Binary and N-ary relations