Table of Contents
Preface
The content of this article is a mixture of these three LinkedIn posts, Towards a New Data Modelling Architecture - Part 2, Atomic Information Resource, and AtomicDB Architecture in R3DM. We also used the full content of the original source from this Mathematica notebook. It is worth mentioning that the term AtomicDB, at that time, was used to signify both the brand-name and the database engine of a company that is now re-branded as X10SYS. R3DM, a vendor-neutral conceptual framework for data modeling, is sharing several fundamental architectural design principles with AtomicDB.
In Part 1 of this series we talked about the main constructs of the Relational and Entity-Relationship data model. In this article we present a computational semiotic analysis of AtomicDB that is based on R3DM and we focus on explaining with an example the universal AIR unit that we will meet again on forthcoming posts of this series.
Background Information
The AtomicDB data model we describe has a long history behind it. Searching at Google for patents with the title “Data base and knowledge operating system” or with the title “Data management architecture associating generic data items using reference” we find several documents that are filed in the year 2003 from the inventor Ron Everett. The same year a “proof of concept” for this invention was successfully demonstrated with a use case of managing a 50+ milion records of spare/repair part requirements for US Navy ships. Today AtomicDB is a fully fledged database management system that is based on Ron Everett’s patented associative data items architecture. According to the vendor several pilots are currently running under big corporations and University research establishments.
AtomicDB Evaluation
The author of this article has been an evaluator of AtomicDB with full access to test GUIs, APIs and web services of their system. In particular he explored their C# API functionality for developers. In order to make tests interactive and efficient most functions of their API have been ported to Wolfram Language using the NETLink C# interconnectivity package. Function calls and other expressions that you see here are based on AtomicDB Mathematica API that is not included with the publication of this article. The Wolfram Language notebook is included for reference purposes.
Entity-Attribute-Value ‘Silo’ Structure
The Entity-Relationship model is universally accepted as the means to extend the relational model in order to give meaning to relationships. For our database example in Part 1 we can draw the following ER diagram.
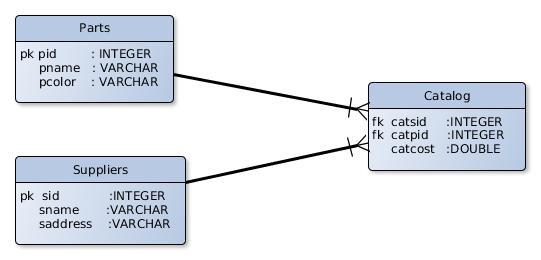
Many-to-Many Relationship
depicts an association among the three entities of our database, Parts, Suppliers and Catalog, and shows the datatypes of their attributes. This is the classic many to many relationship between Parts and Suppliers where the Catalog is the associative entity, also known as the bridge table or join table. Primary and foreign keys are also specified for the names of the attributes that play that role
From a semantic point of view, similar diagrams are in need from users that want to express business processes. But when we reach the implementation stage software engineers have to marry business requirements with the technical constrains of the database system hence the ER diagram you see. This is known as “The Model”, a conceptual view of the user on data. The ER version of the model has several limitations, due to the architecture of RDBMS. One important consideration is that each attribute remains enclosed in the table structure; and in the case the same attribute appears in another table, it has to be repeated. In our example above, the primary key pid of Parts is repeated as a foreign key catpid in Catalog. The difficulties that arise in data aggregation due to this limitation are substantial.
The relational and the entity-relationship model made a huge impact in the IT world for nearly half a century. But during this long period of standardization it meant also one thing, everyone had to comply with the rules and requirements of the model. Everyone had to think in terms of Entity-Attribute-Value or Subject-Predicate-Object as it is known in the RDF semantic model. Programming languages have been affected too from this monolithic way of thinking. Although it proved to be advantageous to program with classes and objects, it created an artificial problem of how to map these onto persistent data structures on the disk, also known as the object-relational impedance mismatch problem.
Knowledge representation frameworks did not escape from this path. Ontologies expressed in OWL followed the same paradigm with classes, attributes, and values. Serialization methods such as JSON (object-name-value) and XML (element-attribute-value) also came after the same rationale. We consider that this is one of the main reasons that noSQL databases appeared on the scene recently. Key-value store, hierarchical semi-structured documents, column based and graph-property data structures are all attempts to provide a solution to this problem. We include a few examples of characteristic forms with comments by Ron Everett in order to contrast them with the alternative data model of AtomicDB.
Table form
When we attempt to use Tables as a storage paradigm for Information we discover that Tables are a namespace bound, non-dynamic, 2-D, structured storage paradigm that has a different structure for every Table in every Database. 1
Each application is developed with unique and special queries written to each specific database design, table layout and named tables, columns and keys.1
Rows of Parts table from a Microsoft Access relational database that we have used in Part 1
(partsList =
SQLExecute[conn,
"select pid,pname from Parts where pid<994",
"ShowColumnHeadings"->True]) // TableForm
Out: 
XML Form
Rows of the table above serialized in XML
<?xml version="1.0" encoding="UTF-8"?>
<dataroot>
<Parts>
<pid>991</pid>
<pname>Left Handed Bacon Stretcher Cover</pname>
<pcolor>Red</pcolor>
</Parts>
<Parts>
<pid>992</pid>
<pname>Smoke Shifter End</pname>
<pcolor>Black</pcolor>
</Parts>
<Parts>
<pid>993</pid>
<pname>Acme Widget Washer</pname>
<pcolor>Red</pcolor>
</Parts>
</dataroot>
Some have hailed XML (RDF and triple stores) as the means to solve the n-dimensional relationship problem, because with it, meta-information can be captured, but XML is plagued with other problems, not the least of which are namespace binding requiring semantic accord, massively replicated tags and data, the heavy overhead of text based processing, the necessity of searching and indexing all the text in every possible XML document for each and every key/ value-tag/data match sought and the distribution of the tagged datasets across innumerable XML documents, stored in 2-D table-referenced 2-D file structures. Add to that list the overhead imposed by using Semantic Web languages and ontologies and the PhD level specialists required to develop and maintain these ‘knowledge’ oriented systems and you get even more namespace entrenchment and hence specialization of the applications developed with it all 1
JSON Form
{
"dataroot": {
"Parts": [
{
"pid": "991",
"pname": "Left Handed Bacon Stretcher Cover",
"pcolor": "Red"
},
{
"pid": "992",
"pname": "Smoke Shifter End",
"pcolor": "Black"
},
{
"pid": "993",
"pname": "Acme Widget Washer",
"pcolor": "Red"
}
]
}
}
Signified-Sign-Signifier Alternative Paradigm
Entity-Attribute-Value bondage highlights the fact that three perspectives, semantics at the conceptual layer, representation at the symbol layer and encoding at the physical layer are mixed in such a way that it is very hard to separate and work with them at distinct levels of abstraction. The R3DM/S3DM conceptual framework is based on the natural process of semiosis where the signified, i.e. concept, entity, attribute and the signifier, i.e. value are referenced through symbols, i.e. signs, at discrete layers. The same philosophy is shared in the architecture of AtomicDB system.
From Data Items in Table to Information Atoms with NO Table
Every table is a silo. Every cell is an atom of data with no awareness of its contexts, or how it fits in to anything beyond its cell. It can be located by external intelligence but on its own it’ s a “dumb” participant in the system - the ultimate disconnected micro - fragment accessible only by knowing the column and the record it exists in. 1
The alternative is to replace the data elements with information at the atomic level of the system. Instead of a data atom in a table, we have an information atom with no table. Information atoms exist in a multi-D vector space unbounded by data structures and know their context, such as a “customer” or a “product”, just like atoms in the physical world “know” they are nitrogen or hydrogen items and behave accordingly. Information atoms also know when they were created, when they were last modified, and what other information atoms of other types are associated with them. They know their parents, their siblings, and their workplace associates. They are powerful little entities and most certainly NOT fragments. Nor are they triple statements requiring endless extraneous indexing 1
AtomicDB is datatype and namespace agnostic, always fully contextualized, and structure free.
AtomicDB Computational Semiotic Analysis in R3DM

AtomicDB Architecture in R3DM
illustrates the architecture of AtomicDB system according to R3DM framework. In particular, there are three layers that enable a computational semiotic analysis on AtomicDB; the semantic (S3), the sign (S2) and the storage (S1). An alternative notation and terminology is information resources (IRes-R3), representations (IRep-R2) and realizations (IRea-R1)
Each layer plays a distinct role and it is clearly separable from the other two. This serves fully the trilateral principle in R3DM. Storage-Realization layer, depicted with green boxes, portrays how AtomicDB system is implemented with .NET framework at the API level. The AtomicDB Core Key-Value primitive data structure is used to build successive nested List Class containers and association types, see [Fig. 3]. This is how the AIR of AtomicDB is realized at (S1).

AtomicDB Association Types
different kinds of linking (AIR) units
At the Sign layer (S2), [Fig. 2], the AIR receives its symbolic representation. A mere list of four integer numbers is adequate to represent efficiently any piece of information. It is the golden ratio in postmodern era data modeling. It can represent types, instances, and properties, and associate these in a hypergraph network. It is truly a web of information resources based on the power of semiosis, with a reference mechanism not built with character strings (URL) but similar to Internet Protocol address (IP). This AIR information representation serves two principal functions; information resource identification and location addressing, i.e. dereferencing and retrieval, but it does not suffer from the identity problem crisis of the RDFised web. The various forms of KeyVector that correspond to the nested data structures at layer (S1) are depicted with purple boxes.
Finally (S3) layer, [Fig. 2], depicted with blue boxes, put information resources in their semantic perspective and order with a four level hierarchical structure of containers. It is the kind of logic that developers use to manage classes, properties and objects (OOP), or tables, records and fields (RDBMS), or objects, keys and values (XML-JSON) and subject, predicate, objects (RDF). But Ron Everett’s approach differs substantially from previous data models. Information resources are not handled by name, they are always represented and function as meaningful 4D number vectors. We escape from the namespace entanglement and alleviate the complexity of linked information by smart (AIR) information resource units that are represented in a uniform way and their digital form can be processed, retrieved and stored efficiently and/or combined to create composite information structures.
An AtomicDB Working Example
In order to understand better the difference between a Namespace bounded DBMS vs an AIR based DBMS we exemplify key points of AtomicDB architecture in R3DM. But before we start unfolding our example we present AtomicDB terminology.
Terminology
-
Data Itemis a particular type of item that holds an atomic piece of data (an atomic value). -
Collection(data set) is a generic container for data items with no duplicates. A collection is similar to the notion of attribute (column) data set in the relational model. -
Nexus itemis a special type of data item whose role is to keep associations with the other data items in a record. Nexus item plays a similar role to that of a record in the relational model. -
Nexus Collectionis a special type of collection which holds nexus items only. Nexus collection act similarly to the primary key column in the relational data model. -
Recordis a set of data items from different collections each associated to the same nexus item (exactly one per record) -
Grouprefers to several collections and associates them. The group is not a container for collections. Each group has one and only one nexus collection. -
Bridge Collectionis a certain type of collection that can be associated with more than one group. Bridge collection act similarly to the foreign key column in the relational data model -
Conceptis a special type of item that represents uniquely one collection of items. A collection can have one or more representative concepts. A concept can be thought as a reference to collection. -
Modelis a generic container for unique concepts that are associated to form higher constructs and relations. Model is similar to a database schema, or view.
Draw Model
We start by designing a simple concept map using the CMAP Tools that corresponds to the ER diagram of [Fig 1.] above.

Schema with CMAP Tools
Entities in this diagram, (Groups - cyan square boxes), are formed by grouping Attributes, i.e. Collections. One or more Attributes (Concepts - oval shape) are shared between two or more Entities and form bridge collections. This is the equivalent notion of the bridge table in relational and entity-relationship theory. A closer examination of the links reveals that they all have the same type, i.e. isRelatedTo, and Attributes are always connected to Entities with that operator. According to R3DM we are examining information resources at (S3) layer.
Add Model
We can import this concept map or alternatively we can create a new Model programmatically by passing its name as a parameter to the addModel function. Then we can use getModelByName function to get back a Key-Value Rule representation of the Model we added to the system:
modelName = "Parts-Suppliers Catalog Model";
addModel[modelName]
Out:
«NETObject[System.Collections.Generic.List`1
[System.Collections.Generic.List`1
[IAMCore_SharpClient.Core_KeyValuePair]]]»
Get Model
(model = getModelByName[modelName]) // printKVP
Out: {0, 3, 13, 256}->"Parts-Suppliers Catalog Model"
The key {0, 3, 13, 256}, i.e. Sign (S2/R2 - IRep), is a reference 4D vector that we use to access the Model item and the value is the string we assigned as the name of the Model. Everything that is stored in AtomicDB has a key with four dimensions (Environment, System, Context, Item) and a value. Each dimension can be semantically interpreted in a different way, but they are always connected hierarchically. This makes AtomicDB fully symmetrical in terms of values, structures and relationships.
Add Concepts
We continue by adding the Concepts of the Model programmatically. The two arguments of function addConceptsByName are the name of the Model and a list of Concept names. The first name in the list signifies a Nexus concept that is used to associate the rest of the concepts in the list.
catalogConceptNames = {"NX_Catalog", "SupplierIdentifier", "PartIdentifier", "PartCost"};
partConceptNames = {"NX_Part", "PartIdentifier", "PartName", "PartColor"};
supplierConceptNames = {"NX_Supplier", "SupplierIdentifier", "SupplierName", "SupplierAddress"};
(catalogConcepts = addConceptsByName[modelName, catalogConceptNames]) // printKVPL2
Out:
{2,1025,256,1}->NX_Catalog
{2,1025,256,2}->SupplierIdentifier
{2,1025,256,3}->PartIdentifier
{2,1025,256,4}->PartCost
(partConcepts = addConceptsByName[modelName, partConceptNames]) // printKVPL2
Out:
{2,1025,256,5}->NX_Part
{2,1025,256,3}->PartIdentifier
{2,1025,256,6}->PartName
{2,1025,256,7}->PartColor
(supplierConcepts = addConceptsByName[modelName, supplierConceptNames]) // printKVPL2
Out:
{2,1025,256,8}->NX_Supplier
{2,1025,256,2}->SupplierIdentifier
{2,1025,256,9}->SupplierName
{2,1025,256,10}->SupplierAddress
The first thing you should notice is that the numbering of dimensions for Concepts does not follow the previous pattern with the Model 4D vector. Semantically this means we have a different system that can be interpreted in the following way:
There are three Groups with four Concepts each added to our Model. Notice that the first three dimensions of the keys remain constant but the last dimension varies to denote instances of Concepts that belong to the same Model. In this case, the Item dimension of the reference key plays the role of the Concept and the Context dimension plays the role of the Model. The other two dimensions are related possibly to the kind of repository, i.e. we are storing information about models, and our localhost database development environment. Contrast this representation with the previous vector {0, 3, 13, 256} where the Item dimension plays the role of the Model. This indicates that reference vectors in AtomicDB are cleverly inter-related; notice the position of number 256 that signifies always the Model in these 4D vectors.
Another critical observation is that PartIdentifier and SupplierIdentifier Concepts are members of more than one Group. These are the Bridge Concepts and play the same role as the primary and foreign keys in relational data sets. But one of the main differences and a great advantage of this approach is that this time data sets are not duplicated. The same Collection of items, i.e. data set of an attribute, can be referenced by many Concepts.
Get Concepts
Verify that all the concepts have been added to our Model
getConceptsFromModelName[modelName] // printKVPL2
Out:
{2,1025,256,1}->NX_Catalog
{2,1025,256,2}->SupplierIdentifier
{2,1025,256,3}->PartIdentifier
{2,1025,256,4}->PartCost
{2,1025,256,5}->NX_Part
{2,1025,256,6}->PartName
{2,1025,256,7}->PartColor
{2,1025,256,8}->NX_Supplier
{2,1025,256,9}->SupplierName
{2,1025,256,10}->SupplierAddress
Add Collections
With the following addCollectionsAutoMapGroupByName function Collections are automatically associated with the Concepts and a Group is added. Notice that both Collections and Models have been created with the same Environment and System dimensions, it is the third dimension Context that differentiates the type of instances, i.e. items.
(catalogCollections =
addCollectionsAutoMapGroupByName[modelName, catalogConceptNames]) // printKVPL2
Out:
{0,3,15,257}->NX_Catalog
{0,3,15,258}->SupplierIdentifier
{0,3,15,259}->PartIdentifier
{0,3,15,260}->PartCost
(partCollections =
addCollectionsAutoMapGroupByName[modelName, partConceptNames]) // printKVPL2
Out:
{0,3,15,262}->NX_Part
{0,3,15,259}->PartIdentifier
{0,3,15,263}->PartName
{0,3,15,264}->PartColor
(supplierCollections =
addCollectionsAutoMapGroupByName[modelName, supplierConceptNames]) // printKVPL2
Out:
{0,3,15,265}->NX_Supplier
{0,3,15,258}->SupplierIdentifier
{0,3,15,266}->SupplierName
{0,3,15,267}->SupplierAddress
And bridging is achieved by having Bridge Collections, {0,3,15,259} and {0,3,15,258} that are equivalent to Bridge Concepts.
Get Collections
Verify that we have added all the collections to the system:
getCollectionsFromModelName[modelName] // printKVPL2
Out:
{0,3,15,257}->NX_Catalog
{0,3,15,258}->SupplierIdentifier
{0,3,15,259}->PartIdentifier
{0,3,15,260}->PartCost
{0,3,15,262}->NX_Part
{0,3,15,263}->PartName
{0,3,15,264}->PartColor
{0,3,15,265}->NX_Supplier
{0,3,15,266}->SupplierName
{0,3,15,267}->SupplierAddress
Add Data Values
Our next step is to add values into a separate system, at the same Environment with that of Concepts using the Item numbers from the Collections above. First we read relational datasets with SQLSelect function and we form Records that are represented with the List built-in symbol of Wolfram Language.
catalogDataSet=SQLSelect[conn,"Catalog","ShowColumnHeadings"->False];
partDataSet = SQLSelect[conn,"Parts","ShowColumnHeadings"->False];
supplierDataSet=SQLSelect[conn,"Suppliers","ShowColumnHeadings"->False];
Then we add records with the addRecordsByName command of our AtomicDB API passing three arguments; the name of the Model, Concept names, and the body of relational dataset that we read in the previous step.
These are the items added to the NX_Catalog nexus collection
addRecordsByName[modelName, catalogConceptNames, catalogDataSet] // printKVPL2
Out:
{2,7,257,1}->1
{2,7,257,2}->2
{2,7,257,3}->3
{2,7,257,4}->4
{2,7,257,5}->5
{2,7,257,6}->6
{2,7,257,7}->7
{2,7,257,8}->8
{2,7,257,9}->9
{2,7,257,10}->10
{2,7,257,11}->11
{2,7,257,12}->12
{2,7,257,13}->13
{2,7,257,14}->14
{2,7,257,15}->15
{2,7,257,16}->16
{2,7,257,17}->17
These are the items added to the NX_Part nexus collection
addRecordsByName[modelName, partConceptNames, partDataSet] // printKVPL2
Out:
{2,8,262,1}->1
{2,8,262,2}->2
{2,8,262,3}->3
{2,8,262,4}->4
{2,8,262,5}->5
{2,8,262,6}->6
{2,8,262,7}->7
{2,8,262,8}->8
{2,8,262,9}->9
These are the items added to the NX_Supplier nexus collection
addRecordsByName[modelName, supplierConceptNames, supplierDataSet] // printKVPL2
Out:
{2,9,265,1}->1
{2,9,265,2}->2
{2,9,265,3}->3
{2,9,265,4}->4
Get Data Values
In order to read back the data values, we use Concepts and the getItemsFromConceptNames function.
For example to get data Items from the Part Concepts we pass the name of the Model and the Concept names for the Part Group:
getItemsFromConceptNames[modelName, partConceptNames] // printKVPL2
Out:
{2,8,262,1}->1
{2,8,262,2}->2
{2,8,262,3}->3
{2,8,262,4}->4
{2,8,262,5}->5
{2,8,262,6}->6
{2,8,262,7}->7
{2,8,262,8}->8
{2,8,262,9}->9
{2,259,259,1}->991
{2,259,259,2}->992
{2,259,259,3}->993
{2,259,259,4}->994
{2,259,259,5}->995
{2,259,259,6}->996
{2,259,259,7}->997
{2,259,259,8}->998
{2,259,259,9}->999
{2,263,263,1}->Left Handed Bacon Stretcher Cover
{2,263,263,2}->Smoke Shifter End
{2,263,263,3}->Acme Widget Washer
{2,263,263,4}->I Brake for Crop Circles Sticker
{2,263,263,5}->Anti-Gravity Turbine Generator
{2,263,263,6}->Fire Hydrant Cap
{2,263,263,7}->7 Segment Display
{2,264,264,1}->Red
{2,264,264,2}->Black
{2,264,264,3}->Silver
{2,264,264,4}->Translucent
{2,264,264,5}->Cyan
{2,264,264,6}->Magenta
{2,264,264,7}->Green
Check that although we have nine records, i.e. nine identifiers for Parts and nine Nexuses respectively, we have only seven color values or seven Part names. This is because in relational data model certain values of a column/attribute are repeated but in Associative Data Model are single instances
In a similar way, to get data Items from the Catalog Concepts we pass the name of the Model and the Concept names for the Catalog Group:
getItemsFromConceptNames[modelName, catalogConceptNames] // printKVPL2
Out:
{2,7,257,1}->1
{2,7,257,2}->2
{2,7,257,3}->3
{2,7,257,4}->4
{2,7,257,5}->5
{2,7,257,6}->6
{2,7,257,7}->7
{2,7,257,8}->8
{2,7,257,9}->9
{2,7,257,10}->10
{2,7,257,11}->11
{2,7,257,12}->12
{2,7,257,13}->13
{2,7,257,14}->14
{2,7,257,15}->15
{2,7,257,16}->16
{2,7,257,17}->17
{2,258,258,1}->1081
{2,258,258,2}->1082
{2,258,258,3}->1083
{2,258,258,4}->1084
{2,259,259,1}->991
{2,259,259,2}->992
{2,259,259,3}->993
{2,259,259,4}->994
{2,259,259,5}->995
{2,259,259,6}->996
{2,259,259,7}->997
{2,259,259,8}->998
{2,259,259,9}->999
{2,260,260,1}->36.1
{2,260,260,2}->42.3
{2,260,260,3}->15.3
{2,260,260,4}->20.5
{2,260,260,5}->124.23
{2,260,260,6}->11.7
{2,260,260,7}->75.2
{2,260,260,8}->16.5
{2,260,260,9}->0.55
{2,260,260,10}->7.95
{2,260,260,11}->12.5
{2,260,260,12}->1.
{2,260,260,13}->57.3
{2,260,260,14}->22.2
{2,260,260,15}->48.6
Notice that values for the PartIdentifier Bridging Concept are not duplicated but they are referenced instead by the same 4D key vectors whether we are in Catalog Group or Part Group.
Assimilation of a Table
So far so good, but in practice everyone is accustomed to the use of tables. Table is the favorite manageable structure and convenient medium of exchanging-exporting/importing datasets. Therefore the challenge is that any alternative solution on data architecture should provide the means to view and handle data in tables with the minimum effort no matter what is the underlying structure. For this reason we continue our example with a comparison of how we retrieve records from a relational table and assimilate this operation to a Group of items that are represented with a nested List of Rules.
A. Relational
SQLExecute[conn, "select * from Parts", "ShowColumnHeadings"->True] // TableForm
Out:

B. Associative
(nexusMemberItems = getItemsFromConceptNames[modelName, "NX_Part"]) // printKVPL2
Out:
{2,8,262,1}->1
{2,8,262,2}->2
{2,8,262,3}->3
{2,8,262,4}->4
{2,8,262,5}->5
{2,8,262,6}->6
{2,8,262,7}->7
{2,8,262,8}->8
{2,8,262,9}->9
partConcepts[0] // printKVPL2
Out:
{2,1025,256,5}->NX_Part
{2,1025,256,3}->PartIdentifier
{2,1025,256,6}->PartName
{2,1025,256,7}->PartColor
records = getAnything[
model,
partConcepts[0],
nexusMemberItems,
setType->enGridType]
Out:
« NETObject
[System.Collections.Generic.List`1
[System.Collections.Generic.List`1
[IAMCore_SharpClient.Core_KeyValuePair]]]»
res = coreKVPL1ToRules /@ records@ToArray[];
res // TableForm
Out:

Key/Value records of Part Items
Review and Discussion
How do we design a data model, how do we connect data, how do we represent information, how do we store or retrieve them ? These are all fundamental questions in data modeling but there is a common key to unlock them. You have to start by defining a primitive information resource, and then understand how one can build complex information structures on top it. And this is because everything in nature or systems follow this kind of abstraction from the simple to the most sophisticated. There are patterns that recur at progressively smaller scales. There are fundamental building blocks that can build higher-order structures.
For more than thirty years, the data modeling world is dominated by records. Records in the form of a row in a table, or in a form of hierarchically structured XML/JSON documents, or in the form of property-graph nodes. Many consider the fundamental structure of RDF triplet, Subject-Predicate-Object, but this can be seen too as a form of a record that confines you to think in terms of a function-functor that maps information resources from a domain set to information resources of a range set. Neither the nature or reference mechanism of these resources, nor their linkage type are defined in a sufficient or efficient manner.
An alternative view on data modeling that can extend and enrich RDF is introduced in this article. It is based on AIR, analyzed with R3DM framework, and exemplified with AtomicDB. AIR is the oxygen that makes this database technology breath. It makes it alive and kicking.
AIR fits perfectly to the duality principle of R3DM conceptual model and the Everything is Represented with a Symbol corollary. There is no better example to think about this than digital representations as sequences of binary digits in the internal memory state of our machines. In a digital computer, everything is represented and addressed at the machine level with sequences of 0s and 1s. In order to represent information, Ron Everett managed to conceive in a similar way at a higher abstracted level an identification and addressing schema of information units. He wrapped atomic data types, such as a string or number, and made them the core of these units and he used a four-dimensional space to uniformly address, identify, bind and encode AIRs. Thus in AtomicDB each AIR unit is a self-referenced and uniquely identified item in a 4D space with sets of 4D references to other AIRs for classification purpose, and embedded data values for querying purpose.
According to R3DM we have three layers of abstraction, the semantic, the sign, and the storage-data layer. The 4D reference type of AIR is the implementation of sign layer and it is bridging the semantic with the storage layer in the most semiotic way. This is a fully apprehensive act of responding to the fact that atomic data types and data structures cannot play sufficiently both the role of encoding and that of representing information. You have to make these two roles distinct. This is exactly what we manage in a beautiful way with these references. The symbolic layer is created in this 4D space and instead of having dissimilar atomic data types and abstract complex data types, you have uniform AIR units and aggregates of them e.g. collections, records, sets and multi-sets that are referenced in exactly the same way .
This is a completely, new, radical perspective on data modeling. It is a turning point and there has to be ample evidence to support claims that DBMS based on this are superior than their counterparts. We are determined to investigate, enhance, and apply that kind of database technology and connect it to the overall semiotic perspective of R3DM conceptual framework. It is possible that R3DM based on AIR can assimilate all other SQL and noSQL and SPARQL queries and data models in a simpler, more intuitive, faster, more secure, highly consistent, and in a large scale. This uniform structural symmetry based on AIR, both in terms of value representation and bi-directional relationships is perhaps the most innovative feature and what will hopefully make AIR the universal atomic information unit in the whole information science field. If not, I am sure that many other similar paradigms in data modeling will be based on this model, because a whole new unexplored path is now open and unimaginable applications of this technology can be turned into a reality.