Table of Contents
Abstract
In this last post for this series Associative Semiotic Hypergraph technology is introduced to the public with a demonstration of a fully functional prototype that is built in OrientDB multi-model DBMS and coded with Wolfram Language. This is the first working prototype that is based on R3DM/S3DM conceptual, computational semiotics framework, the theoretical framework behind our technology.
Introduction
It is remarkable how we turned an electronic device that is processing only 1s and 0s to an inseparable intelligent companion and trustworthy assistant. There is a long historical record of technological achievements in the development of computable information and the interactive engagement of the user. In every step of our technological progress we made systems with better performance, pushing towards a simpler, extensible, modifiable, scalable and generic logic. And the key behind this imaginative use of computers is the captivating abstract thinking process of the human brain. R3DM/S3DM conceptual and logical framework is an attempt to model databases with the very same intimate mechanism that creates models. In this endeavor, there could not be a better theory as the base of R3DM/S3DM other than Aristotle’s Semiosis. Semiotics is the study of meaning-making and it binds semantics with symbolic representation and transformation which is the bread and butter of computer programs and digital storage. R3DM/S3DM is not only conceived along this theory, it is also founded on those semiotic principles.
R3DM Definition
R3DM - Representation(Resource, Realization) or S3DM - Sign(Signified, Signifier) is a computational semiotic framework with a mathematical morphism that formalizes the architectural design of associative hypergraph databases.1
Following this definition we will unfold R3DM/S3DM and explain its main characteristics starting with the classic three layered database architecture.
Architecture Overview
One of the main purposes of Zachman’s conceptual, logical, and physical database design, is to provide data independence at the application-user level. The three layers are in descending levels of abstraction where the conceptual model is the most abstract and the physical data model the least abstract or most concrete.
The conceptual model usually refers to the domain of discourse and describes the semantics of the application without any reference to the database technology. On the contrary, the logical data model implements the concept model in terms of abstract data types, (e.g. List, Set, Map, Graph). In the following list you can see the correspondence between these two layers for five popular data models.
-
Conceptual Schema
-
Logical Structure
Both conceptual and logical layers should act independently of the underlying database engine, i.e. physical data model. The following is an indicative list of what is normally included in this layer.
- Physical Data Storage Organization
Conceptual Perspective
Regarding to the conceptual data model R3DM/S3DM is using terms that are well-known among database experts, i.e. Entities and Attributes. In Code.1 segment we can view instances of Supplier, Part and Catalog Entities and the Attributes that describe them. Remember that in R3DM/S3DM Entities and Attributes play the role of abstract concepts that we associate to create models of our data, they are NOT containers or instances of data.
-
Entityis something that has a discrete, independent existence,- e.g. Eiffel Tower (Building), Apple Inc (Company), Porsche 993 GT2 with a specific VIN (Car)
-
Attributeis a piece of information that describes anEntity- e.g. (referring to the above
Entities) 300m (Height), US$215.639 (Revenue), WP0ZZZ99ZTS392124 (VIN)
- e.g. (referring to the above
-
Associationrepresents:- An N-ary relation of an
Entitywith itsAttributes(see Code.1)
- e.g. Part{ID, Description, Color, Weight}
- e.g. Part998 {998, “Fire Hydrant Cap”, “Red”, 7.2}
- An N-ary relationship between one or more
Entities, sharing one or more commonAttributes, that is defined by the roles they play in the association (see Code.1)
- e.g. Film {StarringActor1, StarringActor2, Director}
- e.g. FilmID { ActorID1, ActorID2, DirectorID }
- An N-ary relation of an
Code.1 - Result sets from SQL queries on Supplier, Part and Catalog tables. The same result sets are drawn in Fig.1 with a hypergraph and in Code.2 segment they are assimilated with AIR units in Associations
Logical Perspective
Changing now our perspective with a focus on the logical building blocks, R3DM/S3DM can be viewed as a hypergraph, Fig.1, comprised of three data structures hyperatoms (hypernodes), hyperbonds (hyperedges), and hyperlinks (edges).
-
A
hyperbondrepresents graphically a complex data structure (e.g. tuple, JSON object). The role ofhyperbondis to connect a set ofhyperatomsin order to form associations -
A
hyperatomrepresents graphically an atomic data item (e.g. record value, a key-value pair of a JSON object). -
A
hyperlinkgraphically speaking is a Graph Edge that connects bidirectionally ahyperatomtohyperbond
A hypergraph of Supplier Part Catalog for Part No. 998 with its four Catalog entries and its four Suppliers. Hyperedges are in green and hyperatoms are in red
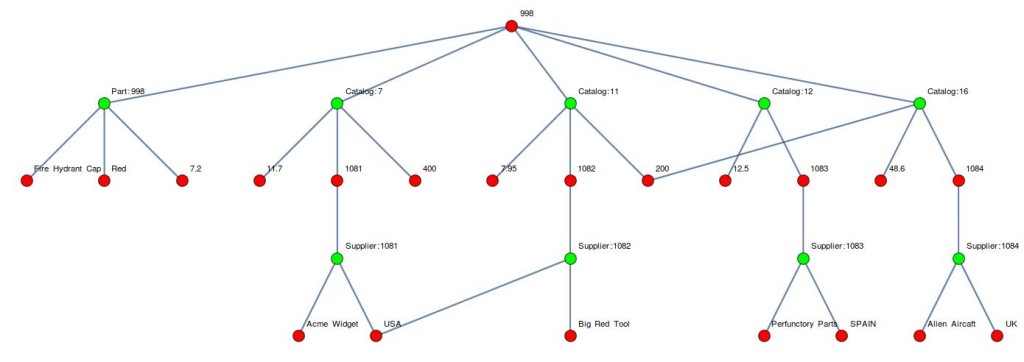
SPC Hypergraph
Instances Perspective
Entity or Attribute in R3DM/S3DM are Types and represent uniquely a single Set of Instances also known as items (see also Items Type System). Entities or Attributes can be thought as references to Collections, Fig.2.
Fig. 2 - Meta Level and Domain Level, i.e. Domain Abstractions and Specializations are abstract types, e.g. a Person, a Credit Card, an Item and refer to the Instance Level. The Instance Level includes domain particular instances, e.g. Tom the person, his Credit Card with No: XXXX, an Item ZZZZ that he purchased
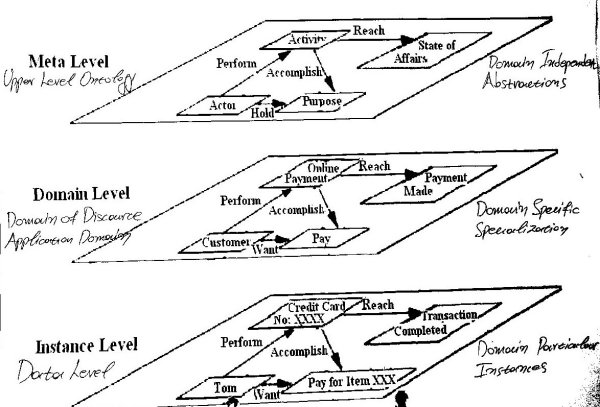
Domain Abstractions and Specializations
-
A
Collection(set of instances) is a generic container for items with no duplicates. ACollectioncan have one or more representative concepts (EntitiesorAttributes). We have two types of collection,Datum CollectionandNexus Collection. -
A
Datum Item(datum) can be thought as an instance of a particularAttributetype that points to a single atomic piece of data (atomic value). ADatum CollectioncontainsDatum Items(data). In our hypergraph perspectiveDatum Itemsare represented withhyperatoms. -
A
Nexus Item(nexus) can be thought as an instance of a particularEntitytype with a role of associating, binding together,Datum Items. ANexus Collectionis a type of collection which holdsNexus items(nexuses). The graphic equivalent ofNexus Itemsis thehyperbond.
Ponder for a moment here, it is a common ground to consider a type, i.e. class, as a container of its instances. But that is not the case in R3DM/S3DM where abstract concepts (types) have an independent existence and refer to collections, i.e. the containers of instances.
This separation between containers of items (instances) and abstract concepts (types) is extremely important as it decouples the data modeling layer from the data collections that are ingested into the databaseSemantic Perspective
Data, e.g. names, codes, quantities, time, location, categorical are meaningless without context. They are separated, isolated bits of information with no related context. Data inherits more meaning when the data are processed within a context. This is exactly the purpose of semantic data modeling, a data modeling technique to define the meaning of data within the context of its interrelationships with other data. Semantic models can be either fact oriented, e.g. RDF triples, or object oriented e.g. Entities and Relationships. The disadvantage of the second is that you have to manage dissimilar 2D structures (tables) that are dependent of a fixed database schema and not connected or related directly. The drawbacks of the first are the labeled edges, the modeling of n-ary relations, the inseparable mixture of plain and typed literal triples that represent values with RDF links that represent resources, the Semantic Web Identity Crisis to name a few. R3DM/S3DM assimilates both fact and object-oriented views by defining an atomic information reference unit which is based on semiotics. Naturally, with this solution we escape from many of the above problems. This is one of the most innovative aspects of this framework.
Object-Oriented View
The most commercially successful semantic model is Entity-Relationship data model. In the first post of this series we discussed the conceptual data model that Chen is using to represent the tuples of relational data model. Fig. 2 and Fig. 3 shows that Chen is using either Entity Set, Attributes and Value Sets or Entity Set(s), Relationship Set(s), Attributes and Value Sets to form an Association. The key point here is that Entity set and Attributes in both cases are separated from the Value sets. Indeed, this is the design principle that is followed in any modern relational DBMS. There is a data dictionary, also known as a metadata repository or metadata registry, that stores among other things names and descriptions of Entity Sets, Relationships and their Attributes that construct a database schema.
Semantically speaking, the database schema and its metadata describe the meaning of its instances, i.e. Entity relations, Entity relationships and Attribute Value sets. For this purpose, in the current OrientDB implementation of R3DM/S3DM each one of these sets is defined explicitly and is represented with an OrientDB Class. There is another reason we keep separate the actual data values. R3DM/S3DM uses a single instance value-based storage. Each unique value in the raw data is stored only once. With this feature there is some resemblance with the data model of Correlation Database.
Network Graph View
While it is helpful to view the higher-level Type System Architecture of R3DM/S3DM through an object-oriented filter, it is important to understand that at a low-level R3DM/S3DM consists of nodes and edges. In particular, the prototype framework we describe in this article is built on top of OrientDB Graph engine with Lightweight Edges and a hypergraph structure, Fig.9.
In previous posts of this series we have made a comparison of the Association construct with Relational tuples, Topic Map Association, RDF triplet, Property Graph nodes and edges and Qlik binary coded records. Such semantic models, with the exception of Qlik technology, are fact oriented and semantics are typically expressed by binary or n-ary relations between data elements. In R3DM/S3DM the graph is usually undirected with symmetric and typed binary relations between the hyperbond and the hyperatom.
This low-level graph view of the system can be implemented in many ways. For example you can have two constructs, e.g. tables, one for the nodes and another for the edges (see the work of Simon Williams in Sentences database), or you can use a key-value store that saves tuples (Graphd the back store of Freebase) or you can also have a native triple store.
Semiotic View
So far we have seen how we can contextualize data using Association construct. This is the mechanism to assimilate tuples of data. Nevertheless, values in a tuple or literals/resources in a triple are meaningless in isolation. In the first case you need either the head and the type of the relation (table and column names), in the second case you need the label and direction on the edge (Predicate) that connects the Subject and the Object to give meaning in the binary relation. To quote Ron Everett,
Every table is a silo. Every cell is an atom of data with no awareness of its contexts, or how it fits in to anything beyond its cell. It can be located by external intelligence but on its own it’ s a “dumb” participant in the system - the ultimate disconnected micro - fragment accessible only by knowing the column and the record it exists in.
and according to him,
The alternative is to replace the data elements with information at the atomic level of the system. Instead of a data atom in a table, we have an information atom with no table.
Ron Everett in “Introduction to Associative Information Systems - (N) Normal Form” {: .small}
Therefore the trick here is to build Associations, based on a uniform representation of its members and the roles they play, in a similar way to Topic Map Association items. For this purpose we have introduced Atomic Information Resource (AIR) unit in the previous post of this series. Now we will view AIR with more detail and in action. For each AIR unit we maintain a record of information. For simplicity and for demonstration purposes, the AIR unit in the current implementation of R3DM/S3DM is equivalent to OrientDB Record ID (RID).
For example the Supplier result set in Code.1 is transformed to an associative set and each cell of Supplier table is represented with an RID (Code.2 - Get Supplier Associative Set). Columns of Part table, e.g. pid (Code.1), and any of its values are also represented with RIDs (Code.2 - Get Datum where Parts.pid=998). The single Part tuple where pid=998, (Code.1) is considered to be an instance of a Entity and has an RID too (Code.2 - Get tuples that this Datum is part of).
Code.2 - Associative sets are presented with values or in RID (reference key) format. The equivalent result sets are drawn in the hypergraph of Fig.1 and fetched with SQL in (Code.1) segment. The document record in OrientDB with RID #60:7 is an instance of prtID Attribute collection. We can read the Datum value, find which Attribute collection (class) it belongs to, and get its siblings, i.e. other Datum items of the class. In the same Datum record we can see its row context associates, i.e. Nexus Items. These are the five tuples it participates, one Part relation (#52:7) and four Catalog relationships (#53:7, #53:11, #53:12, #53:16).
There are two steps towards this transformation of tuples. First we create a value type system, i.e. a place where we store atomic values based on their type. And second we apply a uniform representation on everything, i.e. data and metadata. This turns our DBMS to a Reference Database Management System (RDBMS), i.e. redefining this way the acronym of Relational Database Management Systems. Remember that deep down to an atomic level we store single instance values. It is only the reference keys to those values that we manage. This enables a cellular granularity on R3DM/S3DM. Metadata with a high granularity allows for deeper, more detailed, and more structured information and enables greater levels of technical manipulation.
This uniform Representation and management of abstract information Resources (Models, Data Sources, Metadata) with AIR units in R3DM is the Realization of the fact that underneath there is a separate storage layer of single instance data values. {: .btn .btn–info}
S3DM framework is based on the powerful theory of the semiotic triangle also known as the triangle of meaning or the triangle of reference. We use key references (Signs-Symbols), to represent abstract things (Signified Concepts) in our mind. We encode these into data containers, i.e. forms that the sign takes, for the storage of data values (Signifiers), Fig.3. {: .btn .btn–success}
Fig. 3 - R3DM/S3DM Triangle of Meaning, Semiotic Triangle, Triangle of Reference
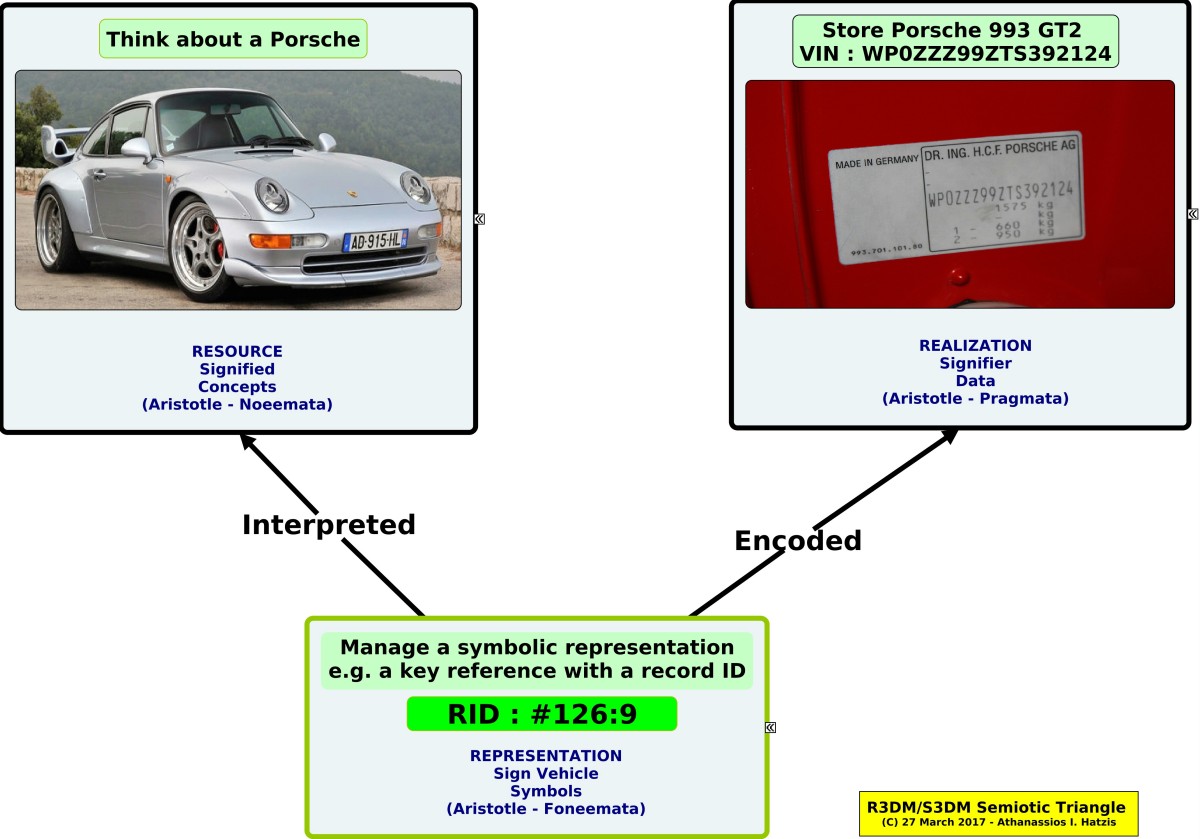
This trilateral principle permits a uniform treatment of semantics, syntax, storage and structure of information based on symbolic representation. The very same principle is applied to the architectural design of R3DM/S3DM type system. {: .btn .btn–info}
Environment Type Systems
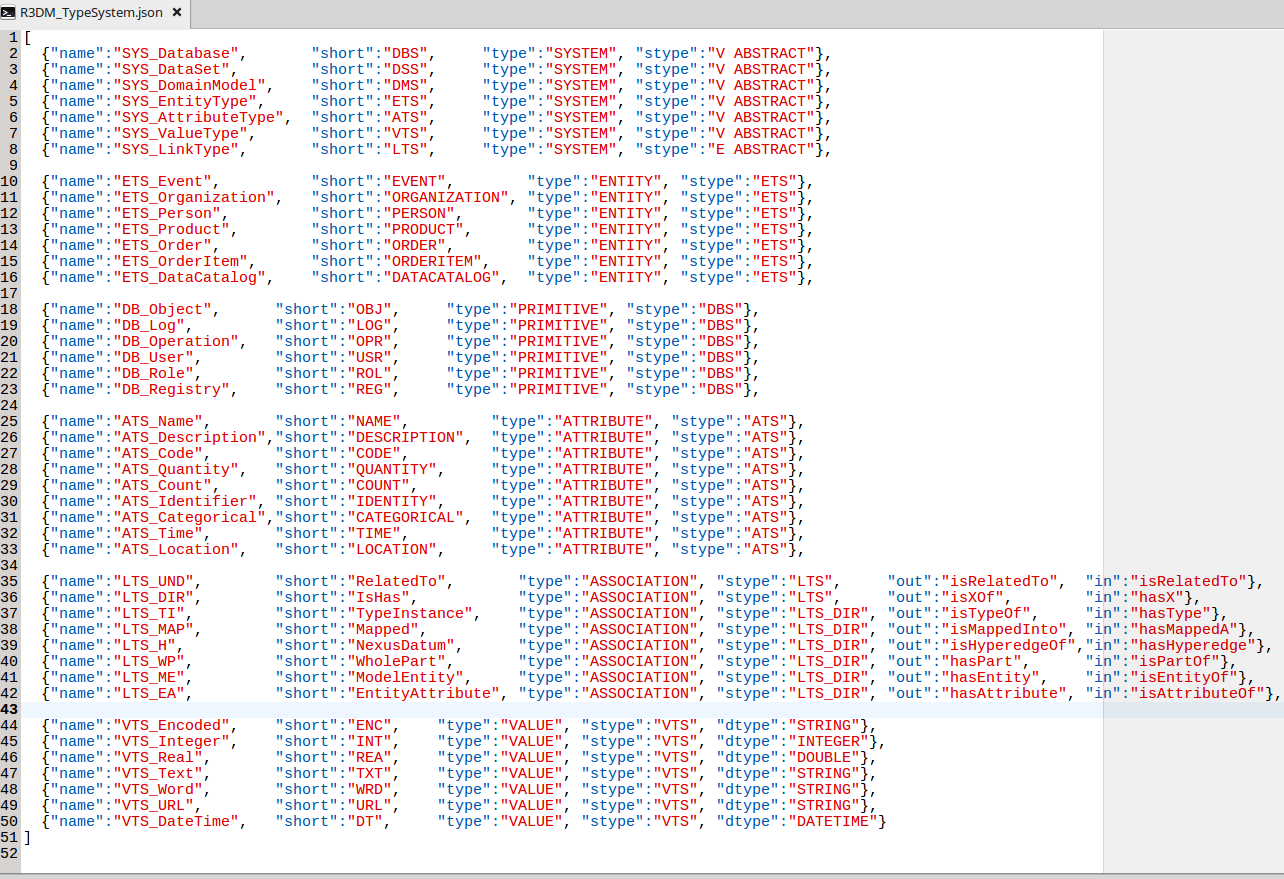
In the previous section we have seen that R3DM/S3DM can be seen from many perspectives. At a lower level we have a network graph of nodes and edges. In OrientDB graph model these are instances of the “V” (for Vertex) and “E” (for Edges) classes. At a higher level, based on those two classes, we build a hierarchically organized namespace in OrientDB paginated local storage (plocal). This is the database Environment, the highest organizational structure, a logical container that it may represent a business environment, a user environment, even a programming environment. Its role is to group related classes into eight type systems. Seven of them manage vertices and one of them is for the different types of edges, Fig.4. The process of initializing and defining the structures in OrientDB database is fully automated by reading the schema of the type system from a JSON file, Fig.5.
Fig. 4 (Left)- Information about R3DM/S3DM hierarchical type system stored in DBRegistry subsystem
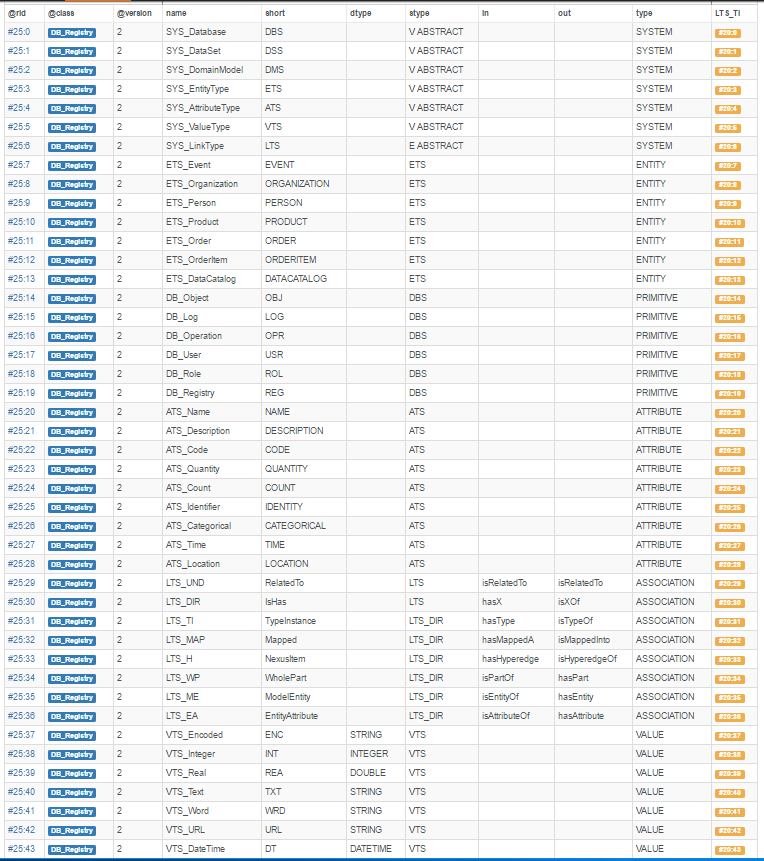
Fig. 5 (Right) - Schema of R3DM/S3DM hierarchical type system in a JSON format. For simplicity, in the current implementation Items Type System (ITS) is not present. Entity Type System (ETS) and Attribute Type System (ATS) OrientDB classes compose this missing system
Our DBAPI project in Wolfram Language has been extended to cover all R3DM/S3DM functionality. For example, an Environment is added with OR3addEnvironment command, (Code.3), and we retrieve any metadata about it with the OR3getAnything command (Code.4).
OR3addEnvironment["F:\tmp\R3DM_TypeSystem.json","R3DB","root","123"]
Code.3 - We pass the schema file (JSON), the name of the database (R3DB), the username and the password. Metadata for the newly created classes are stored in the DBRegistry subsystem Fig.4.
Code.4 - Retrieval of Environment System Types with OR3getAnything command. By default it is returning a List of references (RIDs) unless we specify a specific format for the structure e.g. Dataset.
Database Type System (DBS)
Classes that start with the letters DB such as DBLog, DBUser, DBOperation, and DBUserRole are used to store the user Environment metadata useful for administrative, security, and monitoring purposes (Code.5).
Code.5 - Retrieval of Primitive Database Types with OR3getAnything command as a List of references or as as Dataset.
We have already seen the DBRegistry subsystem where information about the schema of Environment is stored, Fig.4. Another class DBObject is used for casting multi-type role playing at a node (Object is an instance of a Type).
Model Type System (MTS)
Next we will examine how we can add a new domain model in the system. Usually at this stage the database expert draws the entity-relationship diagram of the model which is a graph of Entities, Attributes and relationships. In Fig.6 we present a similar diagram for our Supplier-Part-Catalog data set and in Fig.9 we have drawn the same diagram in OrientDB Graph Editor. The main difference with ER diagrams is that relationships/relations here have a direct representation on the system with the edges (R3DM/S3DM links) and dictionary metadata are explicitly defined and stored in MTS.
Fig. 6 - The schema diagram of SupplierPartCatalog Model (red). Entities (blue boxes) and Attributes (green ovals) are written with their full names (blue) and short names (purple) that take positions outside each shape. Entity boxes inside carry their type (red) and their super-type (blue). While inside each Attribute oval super-type (black) and value type (red) is written. We can also see two types of links. LTS_EA (blue) connects Entities with Attributes and LTS_WP (brown) is linking the model with its Entities.
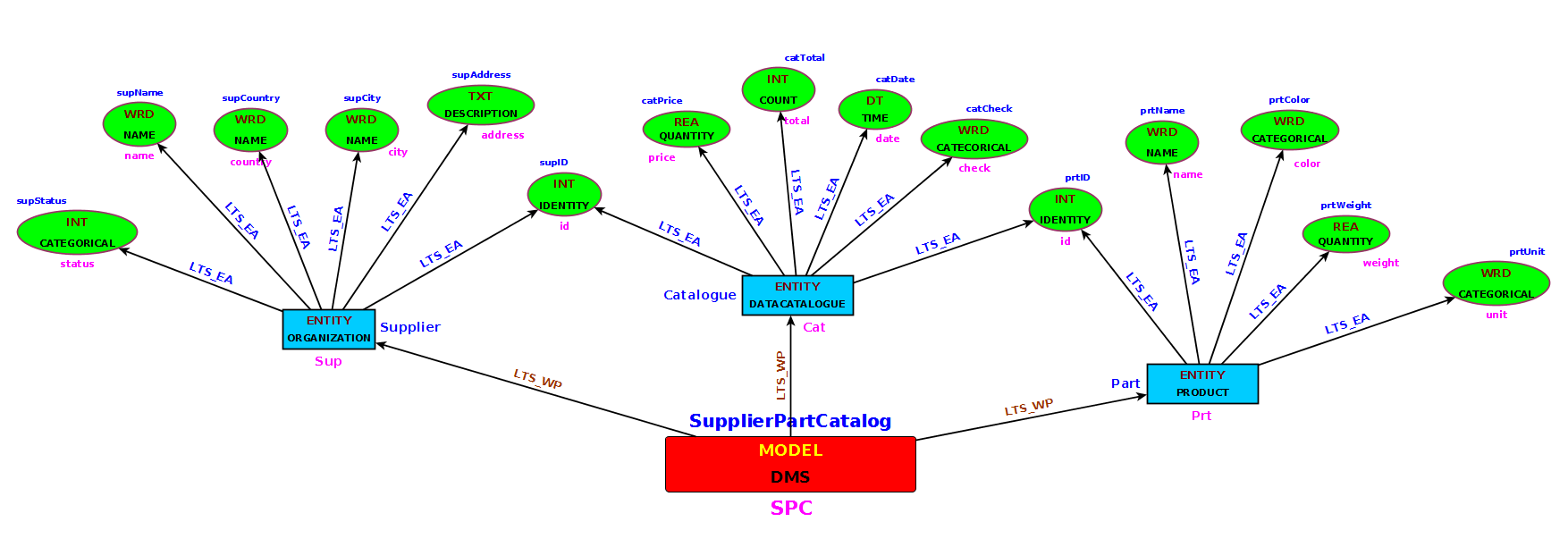
We have serialized the domain model graph of Fig.6 in the same manner as the schema of the type system and the task of loading and building the model is simplified again with the following single function call (Code.6).
OR3addDomainModel["F:\tmp\SPCModel.json"]
Code.6 - The only parameter required in OR3addDomainModel is the schema definition file of the model. This function call will instruct OrientDB to create classes for all Entities and Attributes of the Model. All the metadata from the schema, Fig.6, will be stored in MTS and will be available for retrieval with OR3getAnything command.
Using the powerful OR3getAnything function in the context of DBAPIOrientR3S3 package we can retrieve metadata, Fig.6, for any Model, Entity or Attribute. The result set can be in the form of Wolfram Language Dataset, List, or Graph data structures (Code.7).
Code.7 - Three examples of the OR3getAnything function where we retrieve OrientDB records for Models, Entities and Attributes respectively. The function call is translated to OrientDB RESTful API command and the JSON response from the DBMS is transformed to Wolfram Language data structures for further processing and visualization. It worths noticing the hypergraph representation which is the equivalent graphical form of Model’s schema diagram in Fig.6.
To maintain compatibility and interoperability with ontologies and other vocabularies for structured data on the Internet such as schema.org we categorize Entities and Attributes of any Model according to OrientDB classes that typically form the hierarchical structure of Entity Type System and Attribute Type System.
Entity Type System (ETS)
Entity Types usually refer to abstract entity types. They are used to create schema templates for popular entity types. Metadata are kept in DB_Registry and as usual they can be retrieved with OR3getAnything command (Code.8).
Code.8 - Retrieval of Entity Types with OR3getAnything command from DB_Registry. For each Entity Type we can view its type and its super-type as well as the name and shortname that can be accessed.
As an example consider the schema diagram of Fig.6 where we have three entity sub types, ORGANIZATION, PRODUCT and DATACATALOGUE where we classify the Supplier, Product and Catalogue entity collections respectively (see Code.7, Get Entities section).
Attribute Type System (ATS)
Similarly, Attribute Types refer to abstract attribute types. Each attribute can participate in one or more Entity Types and that is how schema templates are formed. In our Supplier-Product-Catalogue data model, Fig.6, attributes can be classified as CATEGORICAL (Supplier_status, Part_color, Part_unit, Catalog_check), IDENTITY (Supplier_id, Part_id), NAME (Part_nameEN, Supplier_nameEN, Supplier_city, Supplier_country), QUANTITY (Part_weight, Catalog_price), COUNT (Catalog_total), TIME (Catalog_date) and DESCRIPTION (Supplier_address). The following OR3getAnything command demonstrates how we can draw metadata about this type system (Code.9).
Code.9 - Retrieval of Attribute Types with OR3getAnything command from DB_Registry. For each Attribute Type we can view its type and its super-type as well as the name and shortname that can be accessed.
Each of these attribute classes above (see Code.7, Get Attributes section) refers to an attribute collection of data items that has a value type. For example, Supplier_status, Part_id, Catalog_total, Supplier_id are of value type INT (integer) and Part_weight is of value type REA (real).
Items Type System (ITS)
This is the system of items collections, i.e. where Entity and Attribute reference instances are stored (see Instances Perspective). In our demo these are represented with OrientDB classes, Fig.7.
Fig. 7 - Two Select SQL queries with OrientDB Studio manager. The first one returns four Entity records and the second one returns four Attribute records. Each Entity and Attribute record is represented with an item from a collection. These items in turn are represented with a reference key which is OrientDB @rid
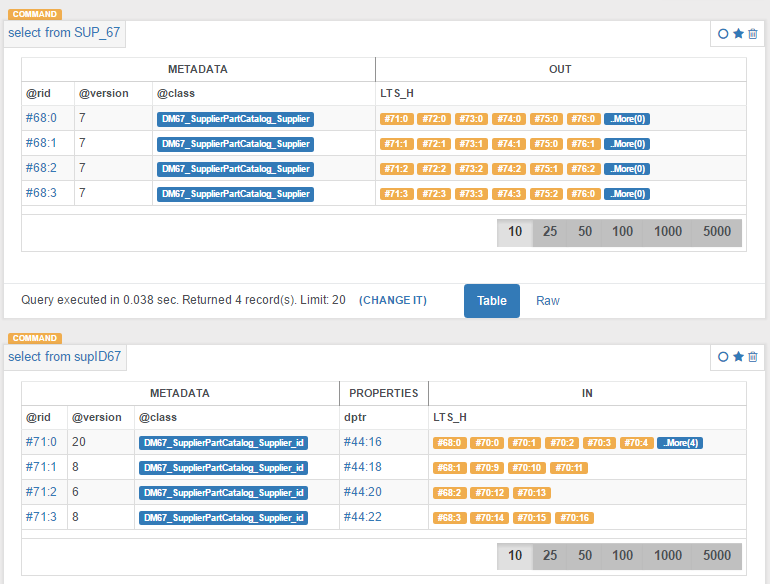
For simplicity’s sake we have not constructed ITS separately but we used OrientDB classes instead to populate them with instances of Entity and Attribute types. Nevertheless the idea is the same, segregate the abstract concepts, TYPES, from the domain particular INSTANCES.
Value Type System (VTS)
According to our Semiotic View (Fig.3) key REFERENCES (RIDs) represent RESOURCES from DBS, MTS, ETS, ATS, ITS, LTS, DSS and encoded form of data, i.e. REALIZATION of data values. These values have domains that are based on OrientDB primitive data types, e.g. Integer, Double, DateTime, String and types that are defined in the Value Type System (VTS), Code.10.
Code.10 - Retrieval of Value Types with OR3getAnything command from DB_Registry. For each Attribute Type we can view its RID, type, super-type, name, shortname and the OrientDB data type that is based on.
Data values are stored together in ordered sets based on Value Types, e.g. all integers in one set (VTS_Integer), identifiers in another (VTS_Encoded), and so on. This optimizes the access and management of values. Each Item Collection is a subset of values, i.e. a subset of a value set, Fig.8.
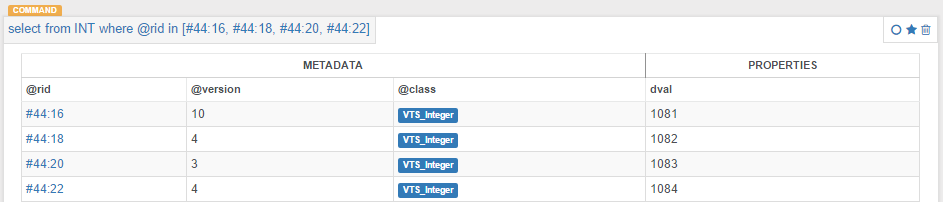
Figure 8:
Fig.8 - A subset of the VTS_Integer value set. This record set is obtained with OrientDB SQL select command. Each one of these records is pointed from a datum item of the Supplier_id collection (see Fig.7) using the OrientDB Link type.
Elements of both Value Sets and Item Collections are unique, i.e. a single instance of each one. In OrientDB this is implemented by setting SB-Tree index with UNIQUE keys in both Value set and Item Collection.
Data Sources Type System (DSS)
Yet there is another type system in R3DM/S3DM framework that is reserved for the input of data sets, the Data Sources Type System (DSS). A Data Set is considered to be a number of related collections that usually correspond to the contents of flat files or database tables. During the process of adding a Data Setwe do not store the values but only the structure and properties, Code.11.
Code.11 - Demonstration of the OR3addDataSet command with three parameters, the name of the new DataSet that will be created, the working path and the filenames of the flat files to inspect. This function call will instruct OrientDB to create a new class to store information about the structure of these flat files. These metadata will be available for retrieval with OR3getAnything command (Code.12).
Code.12 - Retrieval of a DataSet structure, e.g. name, shortname, type, supertype, path, table names, table types, column names, etc, with OR3getAnything command from DSS system.
Link Type System (LTS)
Last but not least the aforementioned symmetric and typed binary relation is a bidirectional link, i.e. hyperlink, that is used to connect a hyperatom to a hyperbond to form Associations. We have two kinds of hyperlinks, directed and undirected. Directed links are used to form directed associations of a specific type, e.g. Entity-Attribute, Whole-Part, Type-Instance Fig.9. Depending on which direction we traverse the link, outgoing or incoming we have two different labels to assist us in reading and understanding the semantics of the binary relation. In all cases metadata about the Link Type System (LTS) are currently stored in DB_Registry and as usual we can retrieve link types with OR3getAnything command, Code.13.
Code.13 - Retrieval of Link Types with OR3getAnything command from DB_Registry. For each ASSOCIATION type we can view its supertype, name, short name, and the labels for outgoing or incoming traversal direction.
Fig.9 - Schema diagram of Supplier-Part-Catalog model in OrientDB Graph Editor. Red edges connect Entities to Attributes and green edge connect the Model to Entities. We can also view the type of R3DM/S3DM link in LTS system as a label on the edge
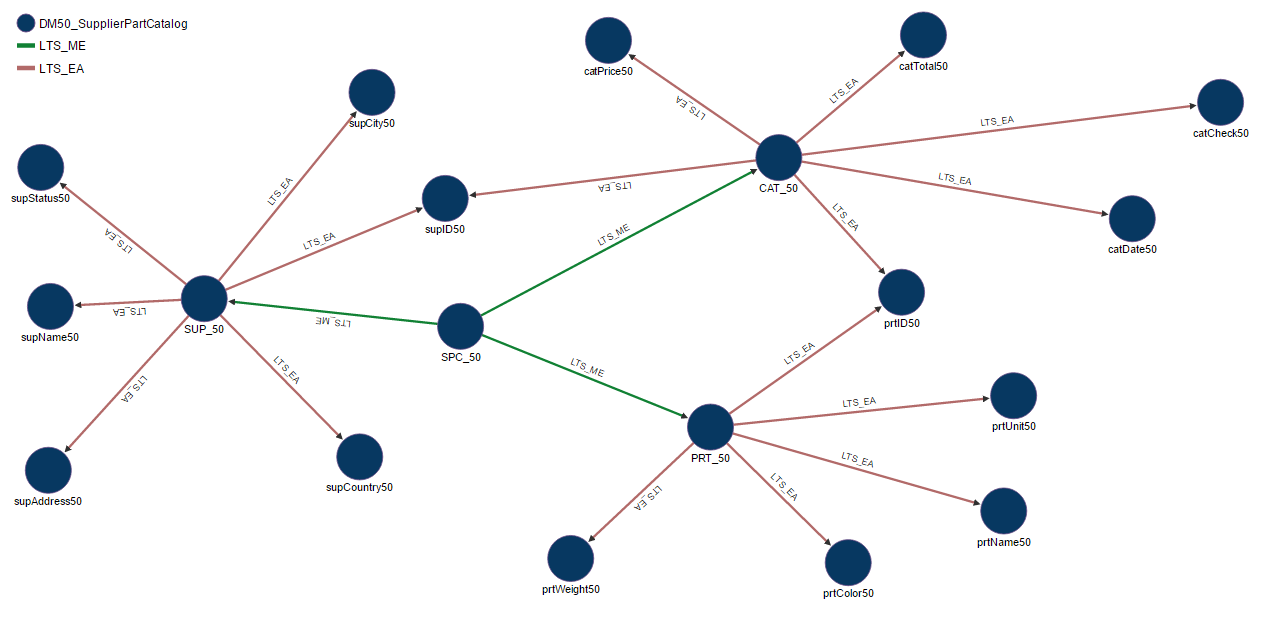
Figure 9:
Functional Operations
The OrientR3S3 Package extends OrientDB RESTful API package in Mathematica with a powerful functional set of commands that cover all operations in R3DM/S3DM. These operations fall in four categories, get, update, delete, add (GUDA). The main idea here is to define standard named optional arguments for any of these functional categories and then allow their values, default or mandatory, to be given using Wolfram Language transformation rules. We have already started viewing examples of this functional approach to data management with the OR3getAnything command, Code.2, Code.4, Code.5, Code.7, Code.8, Code.9, Code.10, Code.12, Code.13.
Get Anything
By varying the named optional arguments we pass to OR3getAnything public function of the OrientR3S3 Package, Code.14, we can retrieve or search for anything in R3DM/S3DM and we can also ask to return the result in a specified format e.g. Dataset, References, Rules, and Associations.
(* Search Operations *)
OR3getAnything[from->"25:02", find->"SPC"]
OR3getAnything[from->"50:01", find->"prtName"]
OR3getAnything[from->"50:02", find->"'Acme Widget Washer'"]
(* Type Systems Operations *)
OR3getAnything[from->"25:19", type->"SYSTEM", return->"Dataset", debug->True, check->True]
OR3getAnything[from->"25:19", type->"PRIMITIVE", return->"Dataset", debug->True]
OR3getAnything[from->"25:19", type->"ASSOCIATION", return->"Dataset"]
OR3getAnything[from->"25:19", type->"VALUE", return->"Dataset"]
OR3getAnything[from->"25:02", type->"MODEL", return->"References"]
OR3getAnything[from->"25:02", type->"ENTITY", return->"Dataset"]
OR3getAnything[from->"25:02", type->"ATTRIBUTE", return->"Dataset"]
OR3getAnything[from->"25:01", type->"DATASET"]
OR3getAnything[from->"25:01", type->"TABLE", return->"Dataset"]
OR3getAnything[from->"25:01", type->"COLUMN", return->"References"]
(* Mapping Operations *)
OR3getAnything[from->"50:2", get->"Mapping", return->"Rules"]
OR3getAnything[from->"50:2", get->"Mapping", return->"Bigraph"]
OR3getAnything[from->supplierMRules, get->"Mapping", return->"AssociationWithValueTypes"]
OR3getAnything[from->supplierMRules, get->"Mapping", return->"AssociationWithNames"]
(* Items Operations *)
OR3getAnything[from->"70:1", get->"Fields"]
OR3getAnything[from->"50:1", get->"Entities", return->"Count"]
OR3getAnything[from->"50:5", get->"Entities", return->"Dataset"]
OR3getAnything[from->"50:2", get->"Attributes", return->"References"]
OR3getAnything[from->"50:2", get->"Model", return->"Names"]
OR3getAnything[from->"50:2", get->"Attributes", return->"RulesWithNames"]
OR3getAnything[from->"50:2", get->"Attributes", return->"Rules"]
OR3getAnything[from->"70:2", get->"Parts", return->"Names"]
OR3getAnything[from->"70:2", get->"Parts", return->"Count"]
OR3getAnything[from->"70:2", get->"Parts", return->"Dataset"]
OR3getAnything[from->"70:5", get->"Whole", return->"References"]
OR3getAnything[from->"70:1", get->"Parts", return->"Rules"]
OR3getAnything[from->"70:1", get->"Parts", return->"RulesWithNames"]
OR3getAnything[from->"50:3", get->"Tuples", return->"Count"]
OR3getAnything[from->"50:3", get->"Tuples", return->"Rules"]
OR3getAnything[from->"50:3", get->"Tuples", return->"References", values->True]
OR3getAnything[from->"50:2", get->"Tuples", return->"Dataset", values->True]
OR3getAnything[from->"50:2", get->"Tuples", return->"Dataset", values->True, filter->"58:0"]
OR3getAnything[from->"50:2", get->"Tuples", return->"FieldsDataset", values->True]
OR3getAnything[from->"50:3", get->"Collections", return->"References", values->True]
OR3getAnything[from->"50:11", get->"DataItems", return->"References", values->True]
OR3getAnything[from->"60:7", get->"Nexuses", return->"Count"]
OR3getAnything[from->"60:7", get->"Nexuses", return->"References"]
OR3getAnything[from->"60:7", get->"Nexuses", return->"Rules"]
OR3getAnything[from->"60:7", get->"Nexuses", return->"Association"]
OR3getAnything[from->"60:7", get->"Nexuses", return->"AssociationWithFields"]
OR3getAnything[from->"60:7", get->"Nexuses", return->"Dataset"]
Code.14 - Examples of the OR3getAnything command from OrientR3S3 Wolfram Language package.
Add anything
We have not reached the development phase of integrating all add operation in an OR3addAnything function of OrientR3S3 Package. Instead of this unified function we have defined many others such as:
-
OR3addEnvironment[ envstruct, envname, usrname, usrpwd ] - Code13 -
OR3addDomainModel[ jsonFileName] - Code6 -
OR3addDataSet[ datasetName, dataSetPath, fileNames] - Code11Thus, we have seen how we can add an Environment Type System, a Domain Model and a Data Source. The last two and those that follow are repetitive actions in data analytics lifecycle, i.e. data sources import, modeling, mapping, ingestion, [filtering and aggregation][].
-
OR3addMapping[columns, attributes, mappingRules] - Code15This is a problem of matching the Columns of a Table or in general fields of a data set with the Attributes of an Entity in a data model.
We can have fields from multiple data sources that are mapped in the same model. The following code section Code15 demonstrates how we perform the mapping of the
Columnsfrom the threeTablesof a data set that we added in Code12.
Code.15 demonstrates the mapping of data fields onto Attributes in three steps. Step1: retrieve metadata from the Data Set and the Model, Step2: specify the mapping rules, Step3: store the mapping.
Mapping is necessary in order to proceed with the data ingestion. This allows seamless integration of data from multiple data sources on the model we design in R3DM/S3DM. The following three add operations are used in populating Entity, Attribute items collections with reference instances and the Value Type System with data values. Records, i.e. tuples, are assimilated by creating associations (Code16).
OR3addValue[className, propertyValue, propertyName] - Code16OR3addNexus[className] - Code16OR3addEdge[edgeClass, fromItem, toItem] - Code16
Code.16 demonstrates the ingestion of three data sources (TSV files). First we read headers and body from each file in memory. Then we get the mapping of Columns from the stored Dataset onto the Attributes of each Entity and finally we add values, collections items and associations.
Filtering
It should have become apparent that R3DM/S3DM operates in a different way than other database models. Instead of a Data definition language, Data manipulation language or a Query language (SQL, SPARQL) the functional, uniform set of commands that we have seen in the previous section due to the consistent structure of its type systems and the AIR units makes it easier to manipulate data and elements of the database.
One of the most characteristic features of R3DM/S3DM is the ability to filter data in a seamless standard way instead of accessing data with a query plan which may vary between database models. {: .btn .btn–info}
This filtering operation is similar to QlikView and we will make a contrast with the same data set and example case we used in the 5th article of this series.
Case1: Condition and Sorting Order
In this case we are looking for the Supplier that has the minimum Catalog Price for a Red Fire Hydrant Cap and we want to retrieve supID, supName, supCity, supCountry, catPrice, catQuantity, prtID, prtName, and prtColor. The following SQL SELECT query and SPARQL query retrieve a result set using the relational or the RDF data model respectively.
Code.17 - SQL query: sort Catalog prices for a Red Fire Hydrant Cap
SELECT suppliers.sid, suppliers.sname, suppliers.scountry,
catalog.catcost, catalog.catqnt,
parts.pid, parts.pname, parts.pcolor
FROM suppliers
INNER JOIN (parts
INNER JOIN [catalog]
ON parts.pid = catalog.catpid)
ON suppliers.sid = catalog.catsid
WHERE (( ( parts.pid ) = 998 ))
ORDER BY catalog.catcost;
Code.18 - SPARQL query: sort Catalog prices for a Red Fire Hydrant Cap
SELECT ?sup ?supName ?supCountry
?catPrice ?catQuantity
?prt ?prtName ?prtColor ?cat where
{
?prt dc:identifier "998"^^xsd:int .
?prt rdf:label ?prtName .
?prt schema:color ?prtColor .
?cat wd:hasPart ?prt .
?cat schema:cost ?catPrice
OPTIONAL {?cat schema:quantity ?catQuantity .}
?cat wd:hasVendor ?sup .
?sup rdf:label ?supName .
?sup schema:country ?supCountry
}
ORDER BY ASC(?catPrice)
Code. 19 - We have coded two solutions for the testing case using our DBAPI OrientR3S3 package. In the first one (see condensed form in Code20) Catalog Tuples are filtered then sorted with a single command ! The first tuple in the resulting set is the one we are looking for. Then we use filtering on Part and Supplier sets to obtain other information. Finally we project and we Join all three tuples deleting any duplicates. In the second solution we start by filtering Catalog collections, then we find the Datum with the minimum Catalog price. Then we filter Catalog, Supplier and Part tuples, we project and join the final tuples.
Code.20 R3DM/S3DM Filtering. This is the condensed version of Code.19
{SUP, PRT, CAT} = OR3getAnything[from->spcModel, get->"Entities"]
prtID = OR3getAnything[from->spcModel, find->"prtID"][[1]]
fval1 = OR3getAnything[from->prtID, find->"998"][[1]]
minCatPriceTuple = SortBy[
OR3getAnything[from->CAT, get->"Tuples", filter->fval1], OR3getValue@#[[3]] &][[1]]
catTuple = minCatPriceTuple // OR3getValue
fval2 = minCatPriceTuple[[1]]
supTuple=OR3getAnything[from->SUP, get->"Tuples", filter->fval2, values->True,][[1]]
prtTuple=OR3getAnything[from->PRT, get->"Tuples", filter->fval1, values->True,][[1]]
prtTuple[[1 ;; 3]]~Join~catTuple[[3 ;; 4]]~Join~supTuple[[{1, 2, 5}]] // DeleteDuplicates
Case2: Condition and Cleansing
This is a case of detecting and correcting an inaccurate value from a record set that is returned by specifying a condition.
Code. 21 - This is an example of cleansing in two phases, detection and correction. Here we can spot the error by filtering collection sets with the condition prtName=Acme Widget Washer. There are two values in prtUnit collection kg and kb. The second one should be kg, it is a typographical error. We can fix this by deleting the hyperlink that connects the nexus 52:3 (red hyperbond), with the datum kb (green hyperatom), and then adding a new hyperlink from 52:3 to datum 64:1.
Case3: Graph Traversal
This is how we perform graph traversal in R3DM/S3DM. Instead of visiting each vertex in the graph we filter hyperbonds on account of the hyperatoms they share.
Code. 22 - We start by specifying a condition, e.g. visiting a single hyperatom. This is a green node on the first hypergraph with the label Acme Widget Washer. Now we can get hyperbonds (red nodes) and find all its siblings. This is also a visual representation of Part tuples. There are two Part items with the description Acme Widget Washer. One has Silver color, the other is Red and both of them weigh 142.88kg. In the same hypergraph we have also two identifiers 993 and 994 these are prtID Attribute values that are shared with Catalog Entity tuples. Therefore in the second hypergraph we have filtered Catalog tuples and we have drawn three of them that are related to these two Part items. This time there are common hyperatoms, those with a supplier identifier (1081, 1084), that are shared between Catalog and Supplier. In the third hypergraph we get a complete 360 degrees view of our case by filtering the Supplier Entity. Now we can see that there are two Suppliers one located in USA that supplies both Part items and the other in UK that supplies only the Silver Acme Widget Washer.
In all three cases we have demonstrated that there are two ways to present the resulting data set from filtering. We can either return item collections, i.e. sets of values for each Attribute we are interested in, or projected tuples from each Entity separately or in a consolidated multi-grid flat form.
Summary
We have presented R3DM/S3DM data modeling framework from a multi-perspective view. The building blocks of conceptual and logical perspective are paired up. Types are separated from instances and semantics are defined and explained with three alternative paradigms object-oriented, network graph and semiotics. It is the interpreted, encoded (materialized) and representative forms in the triangle of reference that gave R3DM/S3DM its name. This trilateral principle is applied to everything including the architectural design of R3DM/S3DM.
The eight type systems of R3DM/S3DM play the role of a formal upper level ontology and its construction is based on the Neurorganon Upper Level Ontology (NULON). Terms of this ontology describe the framework with a hierarchical organizational structure that defines schemata and types for models, entities, attributes, items, values, data sources, links and database metadata.
In terms of querying and managing data there is a set of functional operations that match SQL Select, Insert, Update, Delete statements and there is a filtering mechanism implemented which is equivalent to SQL Where conditions. Thanks to the powerful Wolfram Language transformations we can return results in the form of a table, Rule set, Association set, Dataset, or even a network graph. R3DM/S3DM has also been defined as a functional representation of information resources that are mapped to a materialized form (realization).
Epilogue
R3DM/S3DM is an attempt to unify existing popular data models. The key element to achieve this is the association construct. We have devoted five posts of this series to highlight differences and similarities of Relational, Topic Map, Property Graph, RDF and Qlik data models that are dependent on associations. And the innovative aspect of R3DM/S3DM is that it avoids namespace, addressing, and identification problems by adopting a uniform representation of everything with numerical vector references.
R3DM/S3DM is a framework to construct a Reference Database Management System, it is RDBMS redefined. The first class citizen in this system is the Reference. It is not the tuple of Entity-Relationship data model, or the triplet of RDF/OWL data model, or even the nodes and edges of the graph data model. R3DM/S3DM is based on Atomic Information Reference units (AIR) and it can assimilate table, column, tuple, key-value, triplet, associations and graph data structures. This kind of granularity of R3DM/S3DM controls also the level of information detail that will be presented to the user e.g. show only hyperbonds i.e. Entity instances.
Information resources are not handled by name in R3DM/S3DM, they are always represented and function as meaningful keys (numerical vectors). We escape from the namespace entanglement and alleviate the complexity of linked data by smart AIR units that are represented in a uniform way and their digital form can be processed, retrieved and stored efficiently and/or combined to create composite information structures. Where bit is the basic construction unit for data, AIR becomes the fundamental processing unit for structured information. It is now possible to have a giant global graph (GGG) network of information resources based on the power of semiosis with a reference mechanism that is not built with character strings (URL) but it is similar to the Internet Protocol address (IP).
This is our mantra, build valuable relations; establish effective communications.
The End
… or perhaps the beginning of a new era in databases and data modeling.
Cross-References
- LinkedIn - 20170412 Update about duration, effort and acknowledgements
- LinkedIn - 20170412 Article
- LinkedIn - 20170412 Update about LinkedIn article and request for comments
- LinkedIn - 20170426 Update about RDF predicate and literal triplets
- LinkedIn - 20170525 Update and comment - Post of Theodore Hills - “Data Architecture COMN Sense: Relationships and Semantics”
- LinkedIn - 20170525 Data Modeling Group - Relational-Graph DBMS, how do we bridge the gap ?
- LinkedIn - 20170525 Update and comment - Post of Theodore Hills - “Understand Relational to Understand the Secrets of Data”
- Facebook - 20170412 Post
- Disqus - Number of Comments
- Disqus - Discussion Channel
- Data Science Central - 20170510 Discussion - R3DM/S3DM : A Semiotic Data Modelling Framework
- Data Science Central - 20170525 Discussion Comment on SQL to NoSQL translator
-
© Athanassios I. Hatzis, March 2017 ↩︎